說到聚集索引�,我想每個碼農都明白�����,但是也有很多像我這樣的猥程序員����,只能用死記硬背來解決這個問題����,什么表中只能建一個聚集索引,然后又扯到了目錄查找來幫助讀者記憶����。。����。。問題就在這里�,我們不是學文科,�����,�����,不需要去死記硬背���,�,���,我們需要的就是能看到在眼里面的真實東西�。�����。���。�。��。我們都喜歡聚集索引��,因為它能夠把無序的堆表記錄變成有序���,還玩起了B樹��。��。���。這樣就把復雜度從N降低到了LogMN�����。��。�����。
這樣的話邏輯讀����,物理讀就下來了��。
一:現(xiàn)象
1:無索引的情況
還是老規(guī)矩�,看個例子感受下,首先我有一個Product表�,里面沒有任何索引,如下圖:
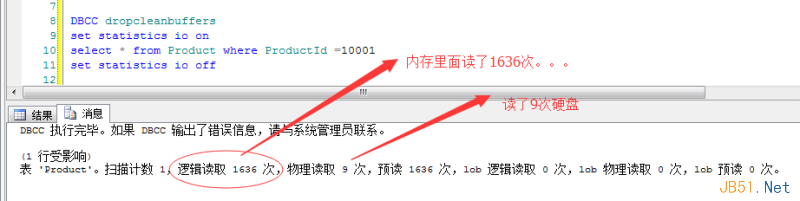
從上圖中,我悲劇的看到了����,物理讀是9次,也就說明走了9次硬盤����,你也可以想到�����,走硬盤的目的是為了拿數(shù)據(jù)���,邏輯讀有1636次��,要注意的是這里的”次“是“頁”的意思����,也就是在內存中走了1636個數(shù)據(jù)頁�����,我用dbcc ind 給你看一下�,是不是有1636個表數(shù)據(jù)頁。
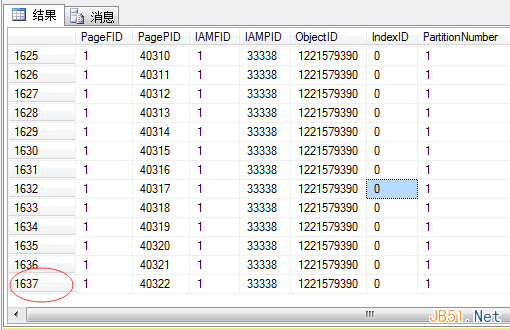
這里有1637個數(shù)據(jù)頁的原因是第一個是IAM跟蹤頁�����。
2:有聚集索引的情況
下面我在Product表中建一個product_idx_productid的聚集索引,然后再次看看io情況���,如下圖:
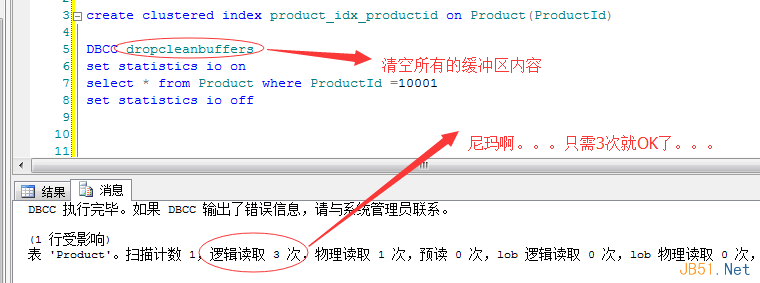
當你看到這個”邏輯讀“為3次的時候���,你是不是已經(jīng)瘋了。����。。在多達1636個數(shù)據(jù)頁中找到目標數(shù)據(jù)���,只需3次���。。�����。����。這個在算法盲看來是不是神
仙下凡��?���??當然�,,�,此物天上有���,人間也有�。��。�。既然有,就應該有一種非常強烈的探索欲���。���。。��。看看這里面到底是怎么玩的���。�。�����。����。。���。
二:探索原理
1:探索葉子節(jié)點
剛才也說了�����,聚集索引玩的就是B樹����,既然是B樹�����,那就有葉子節(jié)點和分支節(jié)點,專業(yè)術語就是度為0的為葉子節(jié)點��,度>0的叫做分支節(jié)點�。。����。。
我想你也聽說了�,聚集索引是將索引列數(shù)據(jù)進行排序后放入B樹,那為了讓你眼見為實���,我先建立一個ID無序的3條記錄���。
復制代碼 代碼如下:
dbcc traceon(3604)
dbcc page(Ctrip,1,120,1)
然后我用dbcc ind 命令查看下3條記錄在哪個數(shù)據(jù)頁中�����,如圖:
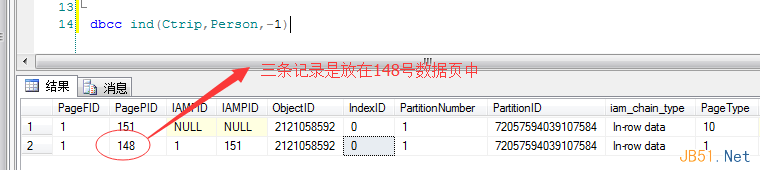
從圖中可以看到���,我的三條記錄是放在148號數(shù)據(jù)頁中的����,然后我導出148號數(shù)據(jù)頁,看看內容是什么����。
復制代碼 代碼如下:
dbcc traceon(3604)
dbcc page(Ctrip,1,173,1)
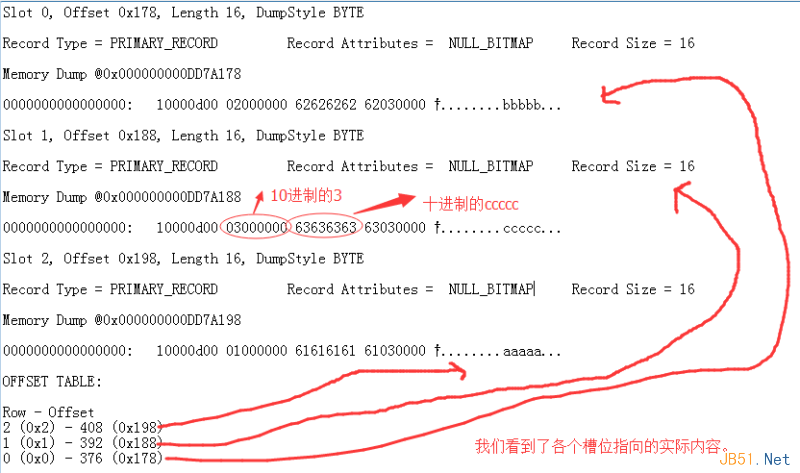
從上圖中,我們看到了”數(shù)據(jù)頁“中的各個槽位的指向是按照表中的實際存儲記錄來的����,好了,下面我創(chuàng)建個聚集索引���,看看實際數(shù)據(jù)是不是真的有序了�����?
復制代碼 代碼如下:
create clustered index Ctrip_idx_ID on Person(ID)
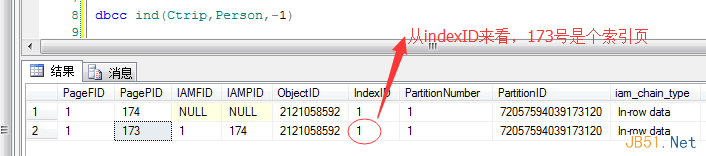
不過在這里有個有趣的問題��,我的148號”表數(shù)據(jù)頁“哪去了��?���??也是夠奇葩的���,換來的確實173號索引頁��,那為了保證數(shù)據(jù)完整性���,應該是把148號數(shù)據(jù)頁的內容灌到173索引頁里面去了吧�����?�?��?�? 沒關系,驗證一下�。
復制代碼 代碼如下:
dbcc traceon(3604)
dbcc page(Ctrip,1,173,1)
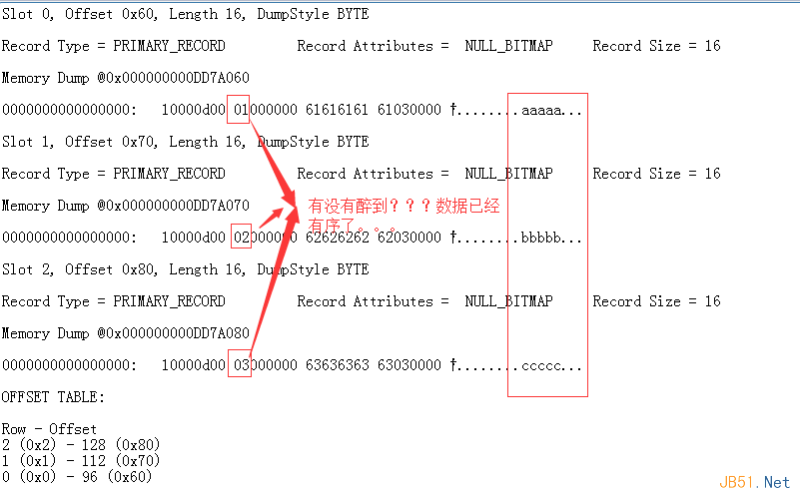
通過上面的圖,有沒有直觀的感覺到�? 數(shù)據(jù)現(xiàn)在已經(jīng)是aaaaa,bbbbb,ccccc的模式了。�����。����。有序啦���。��。���。����。同時索引頁中也保存了148號數(shù)據(jù)
頁的字段值���,比如ID���,Name信息,拿下面的slot0槽位舉例:

到此為止�,我想你對葉子節(jié)點的內容有了個大概的認識,起碼沒有讓你死記硬背了~~~
2 :探索分支節(jié)點
為了讓你看到分支節(jié)點��,我得多灌一些數(shù)據(jù)進去�����,好歹要讓數(shù)據(jù)撐破一個索引數(shù)據(jù)頁��,這樣分支節(jié)點索引數(shù)據(jù)頁就出來了��,看下面的例子:
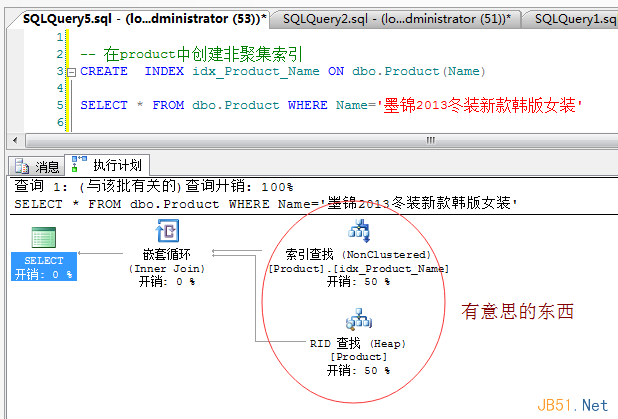
從圖中可以看到,當我插入1000條數(shù)據(jù)的時候�,已經(jīng)出現(xiàn)了一個分支節(jié)點(120號索引數(shù)據(jù)頁),三個葉子節(jié)點(173,121���,126)�,葉子
節(jié)點的數(shù)據(jù)頁內容我也說過了���,現(xiàn)在我很好奇”分支節(jié)點“中保存著什么內容�?���?���?我好興奮,我要導出120號索引數(shù)據(jù)頁了���。�。�。
復制代碼 代碼如下:
dbcc traceon(3604)
dbcc page(Ctrip,1,120,1)
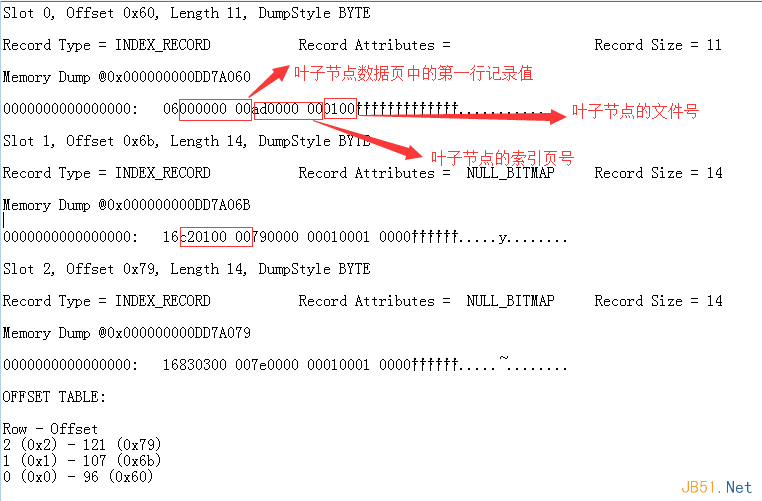
簡單分析下slot0:06000000 00ad0000 000100 的內容
00000000:葉子索引頁中的最小key值(這里有點特殊,除一行記錄不是保存最小值以外����,其余都是的),轉換為十進制就是0��。
ad000000:葉子索引頁的頁號���,轉換為十進制就是173�。
0100:葉子索引頁的文件號���,轉換為十進制就是1.
不過通過分析����,我們看到了�����,其實分支節(jié)點中保存著有兩個值����,一個childpage的minkey,一個childpage的pageid�����,同理,其他的槽位也是這樣�����。
我們換個參數(shù)命令����,讓結果更直觀點,記錄中就是保存著”pageID“和”minKey“�����。
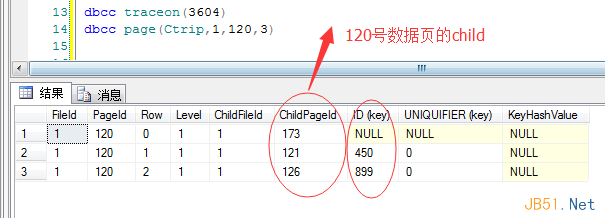
這樣的話�����,我腦海中就有一張圖出來了����,不知道你現(xiàn)在是否有了?�����?��??
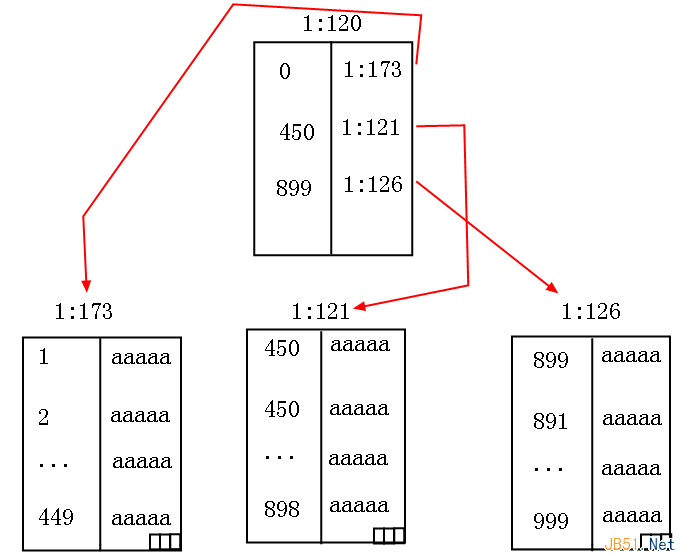
通過上面的分析�,除了第一行記錄不是保存子索引頁中最小key的值外���,其他記錄都是提取子索引頁中的最小索引鍵值���,這一點要注意。���。�。
也許對sqlserver團隊來說�,只要判斷小于449的話就直接去(1:173)數(shù)據(jù)頁,小于889的直接去(1:121)數(shù)據(jù)頁就可以啦����。。�。
當你看到這里的時候,不知道你是否已經(jīng)明白���,為什么表中只能有一個聚集索引呢�����?��?��?好了�,亂雞巴扯了好多,希望對你有所幫助�。
您可能感興趣的文章:- mssql 建立索引
- SQL2000 全文索引完全圖解
- MSSQL 大量數(shù)據(jù)時,建立索引或添加字段后保存更改提示超時的解決方法
- 關于重新組織和重新生成索引sp_RefreshIndex的介紹
- SQL2005CLR函數(shù)擴展 - 關于山寨索引
- MSSQL自動重建出現(xiàn)碎片的索引的方法分享
- Sql Server中的非聚集索引詳細介
- 在SQL SERVER中導致索引查找變成索引掃描的問題分析
- 詳解sqlserver查詢表索引
- SQL2005重新生成索引的的存儲過程 sp_rebuild_index
