2009年���,斯坦福大學李飛飛教授的實驗室發(fā)布ImageNet數(shù)據(jù)集�����,開啟了現(xiàn)代深度學習時代�����。大多數(shù)情況下���,沒有標記的數(shù)據(jù)���,就沒有AI算法模型。模型迭代和調(diào)整���,則需要更多的數(shù)據(jù)���。安全、準確和無偏見的AI系統(tǒng)依賴于大量高質量的訓練數(shù)據(jù)���。
由于缺乏成熟的基礎設施����,構建機器學習系統(tǒng)具有挑戰(zhàn)性。AI進一步發(fā)展的關鍵瓶頸是數(shù)據(jù)——特別是標記數(shù)據(jù)集�����。數(shù)據(jù)是支撐AI的基礎����,每一項人工智能的進步,都離不開基礎數(shù)據(jù)的支持���。
機器學習已然是這個時代最重要的技術變革���,它給世界帶來的總體效益將與互聯(lián)網(wǎng)相媲美。也就是說��,高質量標簽數(shù)據(jù)的瓶頸限制了人工智能僅能在少數(shù)資金充足的科技公司里發(fā)揮作用���。獲取標簽數(shù)據(jù),是構建機器學習模型中最困難的部分����。
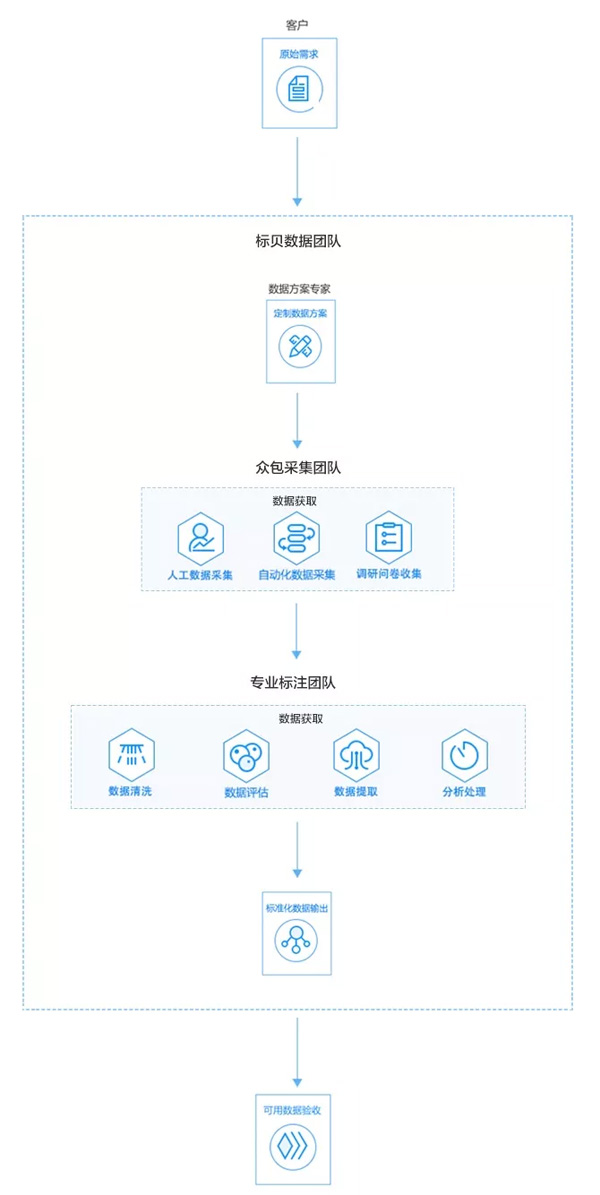
標貝科技深度研發(fā),試圖用人機協(xié)作的方式從語音采集到數(shù)據(jù)標記實現(xiàn)無縫銜接��,攻破行業(yè)技術壁壘。標貝構建了一個遍布世界各地約有萬余名合同工的眾包網(wǎng)絡�����。其核心業(yè)務是為AI及大數(shù)據(jù)領域公司提供數(shù)據(jù)采集��、標注等定制化數(shù)據(jù)解決方案���,服務領域涵蓋圖像�、語音��、文本�、視頻四個方面。
數(shù)據(jù)采集方面�����,可根據(jù)定制化需求�,對各類規(guī)定文本、指定圖片��,各種環(huán)境下的語音����、視頻進行采集����;采集過程中可實現(xiàn)對其內(nèi)容的篩選�、文本化等相關任務?���?沙休d千萬級別以上樣本的收集,單日完成10萬+樣本采集�����。
數(shù)據(jù)標注方面�,通過對圖像、文本�、音頻、視頻等信息進行搜集�����、評估����、歸類��,最終完成標注;標注過程中可實現(xiàn)對內(nèi)容進行關鍵詞等內(nèi)容的提取�����、清洗�、脫敏、校驗等相關任務���。
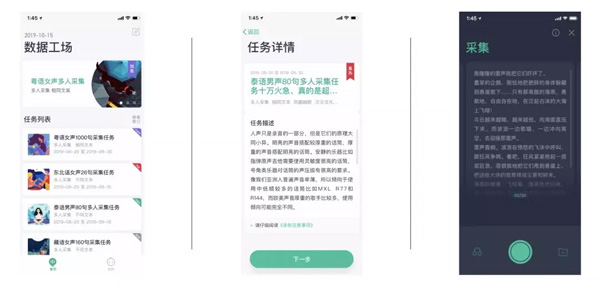
標貝科技旗下全新的人工智能數(shù)據(jù)眾包平臺——數(shù)據(jù)工場�����,正在以專業(yè)����、高效����、安全等優(yōu)勢,助力全球人工智能企業(yè)的研究和進步�。數(shù)據(jù)工場的數(shù)據(jù)服務全球客戶,數(shù)據(jù)類型覆蓋全行業(yè)�����,自有數(shù)據(jù)集和定制化數(shù)據(jù)服務能夠滿足不同行業(yè)、多類型的數(shù)據(jù)需求�����。標貝數(shù)據(jù)服務深耕行業(yè)多年��,目前����,BAT、網(wǎng)易����、滴滴、京東�����、小米�����、喜馬拉雅和搜狗等知名企業(yè)的機器學習團隊陸續(xù)在使用該平臺完成數(shù)據(jù)相關需求�����。
數(shù)據(jù)工場首次將數(shù)據(jù)格式算法融入其中��,通過操作平臺嚴格控制前端采集格式�����,大幅度提升了數(shù)據(jù)的高質量和準確性�����,確保數(shù)據(jù)在采集和上傳的過程中無任何壓縮問題�����。全新的品牌視覺設計融入了多類型數(shù)據(jù)元素�,卡片式交互使產(chǎn)品全方位提升用戶體驗。
產(chǎn)品特色:
- 多類型任務隨心領取��、關鍵標簽一覽無遺��;
- 直擊任務核心信息���、一鍵領取開始采集�����;
- 卡片交互易操作��、采集上傳高效率�����。
數(shù)據(jù)工場產(chǎn)品負責人張亞偉表示:“反復雕琢產(chǎn)品的每一處細節(jié)���,精益求精”�。
數(shù)據(jù)工場以全新的品牌視覺���、順暢的操作體驗和強大的算法能力問世�����。作為AI數(shù)據(jù)服務行業(yè)的引領者���,標貝一直秉承“數(shù)據(jù)服務技術,技術服務生活”的使命�,為促進語音行業(yè)發(fā)展、學術交流��、合作伙伴,標貝提供多種類�����、大規(guī)模�����、高質量的數(shù)據(jù)服務���。
各大應用市場搜索“數(shù)據(jù)工場”或掃描下方“二維碼”先人一步體驗服務。