分享人介紹:王團結,七牛數(shù)據(jù)平臺工程師,主要負責數(shù)據(jù)平臺的設計研發(fā)工作�。關注大數(shù)據(jù)處理,高性能系統(tǒng)服務���,關注Hadoop、Flume�����、Kafka���、Spark等離線���、分布式計算技術����。
下為討論實錄
數(shù)據(jù)平臺在大部分公司屬于支撐性平臺����,做的不好立刻會被吐槽,這點和運維部門很像���。所以在技術選型上優(yōu)先考慮現(xiàn)成的工具�,快速出成果�,沒必要去擔心有技術負擔。早期�����,我們走過彎路��,認為沒多少工作量����,收集存儲和計算都自己研發(fā)�,發(fā)現(xiàn)是吃力不討好��。去年上半年開始�����,我們全面擁抱開源工具�����,搭建自己的數(shù)據(jù)平臺�。
數(shù)據(jù)平臺設計架構
公司的主要數(shù)據(jù)來源是散落在各個業(yè)務服務器上的半結構化的日志(系統(tǒng)日志、程序日志�、訪問日志、審計日志等)��。大家有沒考慮過為什么需要日志����?日志是最原始的數(shù)據(jù)記錄,如果不是日志���,肯定會有信息上的丟失。說個簡單的例子�,需求是統(tǒng)計nginx上每個域名的的流量����,這個完全可以通過一個簡單的nginx模塊去完成���,但是當我們需要統(tǒng)計不同來源的流量時就法做了�。所以需要原始的完整的日志�。
有種手法是業(yè)務程序把日志通過網(wǎng)絡直接發(fā)送出去,這并不可取����,因為網(wǎng)絡和接收端并不完全可靠,當出問題時會對業(yè)務造成影響或者日志丟失���。對業(yè)務侵入最小最自然的方式是把日志落到本地硬盤上�。
Agent設計需求
每臺機器上會有一個agent去同步這些日志�,這是個典型的隊列模型,業(yè)務進程在不斷的push���,agent在不停的pop���。agent需要有記憶功能,用來保存同步的位置(offset),這樣才盡可能保證數(shù)據(jù)準確性�����,但不可能做到完全準確��。由于發(fā)送數(shù)據(jù)和保存offset是兩個動作��,不具有事務性����,不可避免的會出現(xiàn)數(shù)據(jù)不一致性情況,通常是發(fā)送成功后保存offset��,那么在agent異常退出或機器斷電時可能會造成多余的數(shù)據(jù)�����。
agent需要足夠輕���,這主要體現(xiàn)在運維和邏輯兩個方面���。agent在每臺機器上都會部署,運維成本���、接入成本是需要考慮的����。agent不應該有解析日志��、過濾���、統(tǒng)計等動作��,這些邏輯應該給數(shù)據(jù)消費者�����。倘若agent有較多的邏輯�����,那它是不可完成的����,不可避免的經(jīng)常會有升級變更動作��。
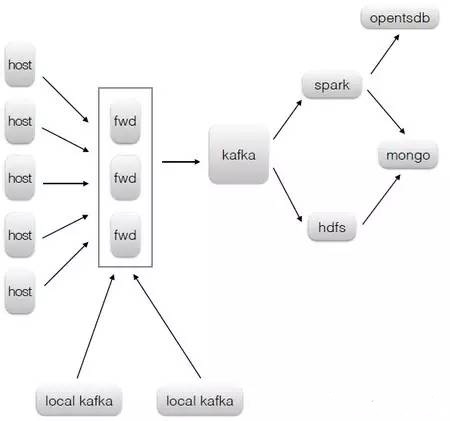
數(shù)據(jù)收集流程
數(shù)據(jù)收集這塊的技術選擇�����,agent 是用go自己研發(fā)的,消息中間件kafka���,數(shù)據(jù)傳輸工具flume���。說到數(shù)據(jù)收集經(jīng)常有人拿flume和kafka做比較,我看來這兩者定位是不同的����,flume更傾向于數(shù)據(jù)傳輸本身,kakfa是典型的消息中間件用于解耦生產(chǎn)者消費者����。
具體架構上,agent并沒把數(shù)據(jù)直接發(fā)送到kafka�,在kafka前面有層由flume構成的forward。這樣做有兩個原因
1. kafka的api對非jvm系的語言支持很不友好�����,forward對外提供更加通用的http接口
2. forward層可以做路由、kafka topic和kafka partition key等邏輯,進一步減少agent端的邏輯
forward層不含狀態(tài)�����,完全可以做到水平擴展�,不用擔心成為瓶頸�。出于高可用考慮,forward通常不止一個實例�,這會帶來日志順序問題�����,agent 按一定規(guī)則(round-robin�、failover等)來選擇forward實例,即使kafka partition key一樣�����,由于forward層的存在����,最終落入kafka的數(shù)據(jù)順序和 agent發(fā)送的順序可能會不一樣。我們對亂序是容忍的�����,因為產(chǎn)生日志的業(yè)務基本是分布式的����,保證單臺機器的日志順序意義不大����。如果業(yè)務對順序性有要求�,那得把數(shù)據(jù)直接發(fā)到kafka,并選擇好partition key��,kafka只能保證 partition級的順序性���。
跨機房收集要點
多機房的情形����,通過上述流程����,先把數(shù)據(jù)匯到本地機房kafka 集群,然后匯聚到核心機房的kafka���,最終供消費者使用�。由于kafka的mirror對網(wǎng)絡不友好�,這里我們選擇更加的簡單的flume去完成跨機房的數(shù)據(jù)傳送。
flume在不同的數(shù)據(jù)源傳輸數(shù)據(jù)還是比較靈活的���,但有幾個點需要注意
1. memory-channel效率高但可能有丟數(shù)據(jù)的風險�,file-channel安全性高但性能不高。我們是用memory-channel����,但把capacity設置的足夠小,使內存中的數(shù)據(jù)盡可能少�,在意外重啟和斷電時丟的數(shù)據(jù)很少。個人比較排斥file-channel���,效率是一方面,另一個是對flume的期望是數(shù)據(jù)傳輸�����,引入file-channel時����,它的角色會向存儲轉變,這在整個流程中是不合適的�。通常flume的sink端是kafka和hdfs這種可用性和擴張性比較好的系統(tǒng),不用擔心數(shù)據(jù)擁堵問題�����。
2. 默認的http souce 沒有設置線程池,有性能問題���,如果有用到���,需要自己修改代碼。
3. 單sink速度跟不上時�,需要多個sink。像跨機房數(shù)據(jù)傳輸網(wǎng)絡延遲高單rpc sink吞吐上不去和hdfs sink效率不高情形�����,我們在一個channel后會配十多個sink����。
Kafka使用要點
kafka在性能和擴展性很不錯,以下幾個點需要注意下
1. topic的劃分�,大topic對生產(chǎn)者有利且維護成本低,小topic對消費者比較友好��。如果是完全不相關的相關數(shù)據(jù)源且topic數(shù)不是發(fā)散的����,優(yōu)先考慮分topic。
2. kafka的并行單位是partition�,partition數(shù)目直接關系整體的吞吐量��,但parition數(shù)并不是越大越高����,3個partition就能吃滿一塊普通硬盤io了���。所以partition數(shù)是由數(shù)據(jù)規(guī)模決定�,最終還是需要硬盤來抗��。
3. partition key選擇不當���,可能會造成數(shù)據(jù)傾斜。在對數(shù)據(jù)有順序性要求才需使用partition key�。kafka的producer sdk在沒指定partition key時,在一定時間內只會往一個partition寫數(shù)據(jù)����,這種情況下當producer數(shù)少于partition數(shù)也會造成數(shù)據(jù)傾斜,可以提高producer數(shù)目來解決這個問題���。
數(shù)據(jù)到kafka后��,一路數(shù)據(jù)同步到hdfs����,用于離線統(tǒng)計。另一路用于實時計算�����。由于今天時間有限�,接下來只能和大家分享下實時計算的一些經(jīng)驗
實時計算我們選擇的spark streaming。我們目前只有統(tǒng)計需求�����,沒迭代計算的需求����,所以spark streaming使用比較保守,從kakfa讀數(shù)據(jù)統(tǒng)計完落入mongo中�����,中間狀態(tài)數(shù)據(jù)很少�。帶來的好處是系統(tǒng)吞吐量很大,但幾乎沒遇到內存相關問題
spark streaming對存儲計算結果的db tps要求較高�。比如有10w個域名需要統(tǒng)計流量,batch interval為10s,每個域名有4個相關統(tǒng)計項�,算下來平均是4w tps,考慮到峰值可能更高�,固態(tài)硬盤上的mongo也只能抗1w tps,后續(xù)我們會考慮用redis來抗這么高的tps
有外部狀態(tài)的task邏輯上不可重入的�����,當開啟speculation參數(shù)時候���,可能會造成計算的結果不準確�。說個簡單的例子
這是個把計算結果存入mongo的task
這個任務�,如果被重做了,會造成落入mongo的結果比實際多�。
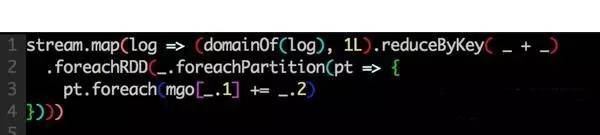
有狀態(tài)的對象生命周期不好管理,這種對象不可能做到每個task都去new一個�����。我們的策略是一個jvm內一個對象�����,同時在代碼層面做好并發(fā)控制�����。類似下面��。
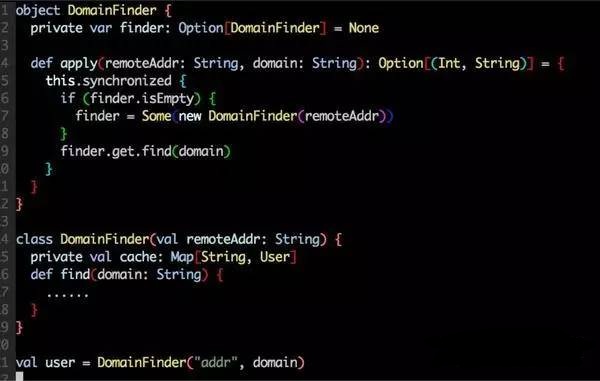
在spark 1.3的后版本��,引入了 kafka direct api試圖來解決數(shù)據(jù)準確性問題�����,使用direct在一定程序能緩解準確性問題�,但不可避免還會有一致性問題。為什么這樣說呢�?direct api 把kafka consumer offset的管理暴露出來(以前是異步存入zookeeper),當保存計算結果和保存offset在一個事務里����,才能保證準確。
這個事務有兩種手段做到�����,一是用mysql這種支持事務的數(shù)據(jù)庫保存計算結果offset�����,一是自己實現(xiàn)兩階段提交。這兩種方法在流式計算里實現(xiàn)的成本都很大��。
其次direct api 還有性能問題��,因為它到計算的時候才實際從kafka讀數(shù)據(jù)���,這對整體吞吐有很大影響�。
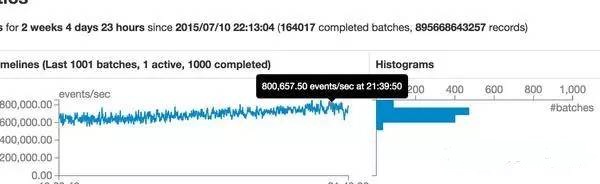
要分享的就這些了�����,最后秀下我們線上的規(guī)模�����。flume + kafka + spark 8臺高配機器����,日均500億條數(shù)據(jù),峰值 80w tps����。