用戶分層��,是基于大方向的劃分�����,你希望用戶朝什么核心目標努力,而用戶分群�����,則是將他們切分更細的粒度提高效果�����。兩者是相輔相成的�。

什么是用戶運營?
它以最大化提升用戶價值為目的����,通過各類運營手段提高活躍度、留存率或者付費指標����。在用戶運營體系中,有一個經典的框架叫做AARRR����,即新增、留存��、活躍、傳播�、盈利(歷史文章已經涉及了)。
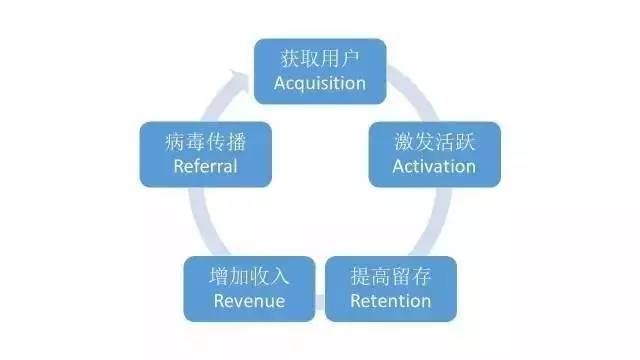
用戶分層
然而����,從用戶活躍到盈利,不是兩個簡單的步驟�����。如果用戶打開產品既算活躍�,就一定能保證商業(yè)模式盈利?優(yōu)秀的用戶運營體系���,應該是動態(tài)的演進��。
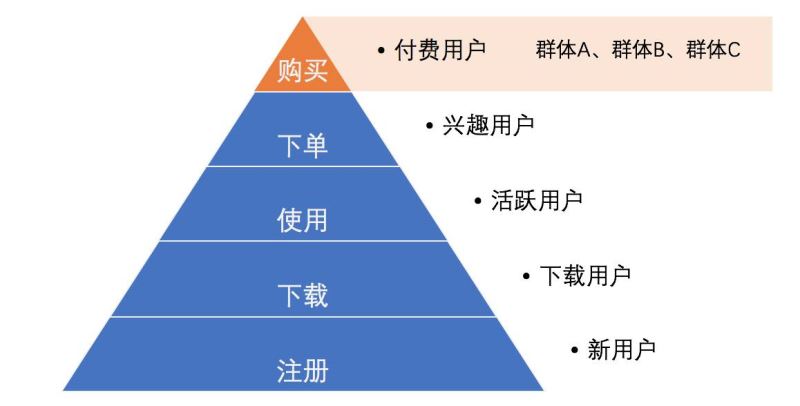
演進是一種金字塔層級的用戶群體劃分�����,上下層呈依賴關系。
首先����,用戶群體的狀態(tài)會不斷變化����。以電商為例����,他們會注冊,下載�����,使用產品���,會推薦���,評價,購買以及付費��,也會注銷���、卸載���、和流失。從運營角度看�,我們會引導用戶做我們想要他做的事(這里是付費)�����,這件事叫核心目標��。
核心目標當然不是一蹴而就的�����,用戶要經歷一系列的過程����。
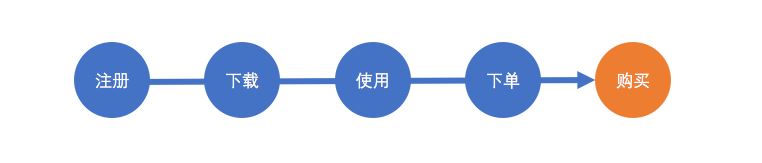
也不是所有的用戶會按照我們設想完成步驟��,各步驟會呈現漏斗狀的轉化�。我們把整個環(huán)節(jié)看作用戶群體的演進。
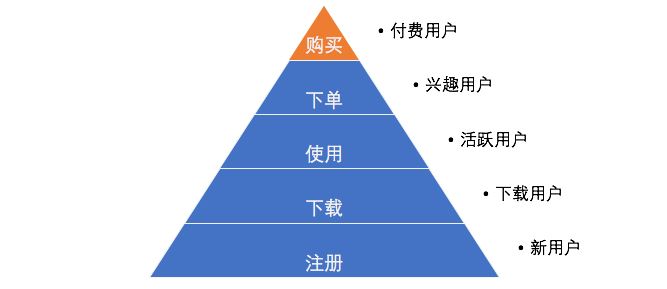
上圖就是一個典型的自下而上的演進��,概括了用戶群體的理想行為�����。
既然用戶群體是不再是一個簡單的整體���,運營們也就無法一刀切的粗暴運營了�,而是需要根據不同人群針對性運營�。這既叫精細化策略,也叫做用戶分層�。
它對運營們的最大價值,就是通過分層使用不同策略���。
新用戶:我希望他們能下載產品��,常用的策略是新用戶福利��;
下載用戶:我希望他們能使用產品����,此時應該用新手引導����,讓他熟悉。
活躍用戶:我希望加深他們使用產品的頻率���,那么運營人員要持續(xù)的運營�����,固化用戶的使用習慣��,并且對產品內容感興趣��;
興趣用戶:我希望他們完成付費決策��,購買商品��,運營可以使用不同的促銷和營銷手段�����;
付費用戶:這是我的目標用戶�����,我也希望用戶能一直維持這狀態(tài)�。
不同的用戶層級,采取的手段不同���。運營同樣會受資源的限制��,當我們只能投入有限資源的時候����,往往會選擇核心群體,即上文的付費用戶們��。因為根據二八法則��,只有核心群體能貢獻最大的價值����。
一個典型的例子是����,在游戲公司,會有專門的人工客服甚至電話專線服務人民幣玩家����,聲音甜美。普通玩家可能是萬年不變的自動回復�����。
想必大家已經了解分層����,那么應該怎么劃分?
其實分層并沒有固定的方式�����,只能根據產品形態(tài)設立因地制宜的體系。不過它有一個中心思想:根據指標劃分��,因為指標是一種可明確衡量的標準���,遠優(yōu)于運營人員的經驗直覺�����。

上圖是一個簡化的游戲用戶分層�����,每層指標都是可量化的����。為了上下層用戶清晰����,群體間應盡量獨立,即計算RMB玩家時�,應該把土豪玩家排除,計算普通玩家時�����,應該把結果中包含的上兩層排除,這樣運營的針對性才強����。
之后運營人員可以依此構建分層報表,通過數據趨勢�,制定各種方式來提高數據�。

接下來,我們想一下知乎的用戶分層是什么樣的形式�����?它的核心是大V生產內容�����?還是更多用戶參與Live獲得營收����?挺難決斷的,其實很多運營體系�����,用戶分層是兩層結構。
它以兩個相輔相成的核心作目標����,以此形成雙金字塔分層。
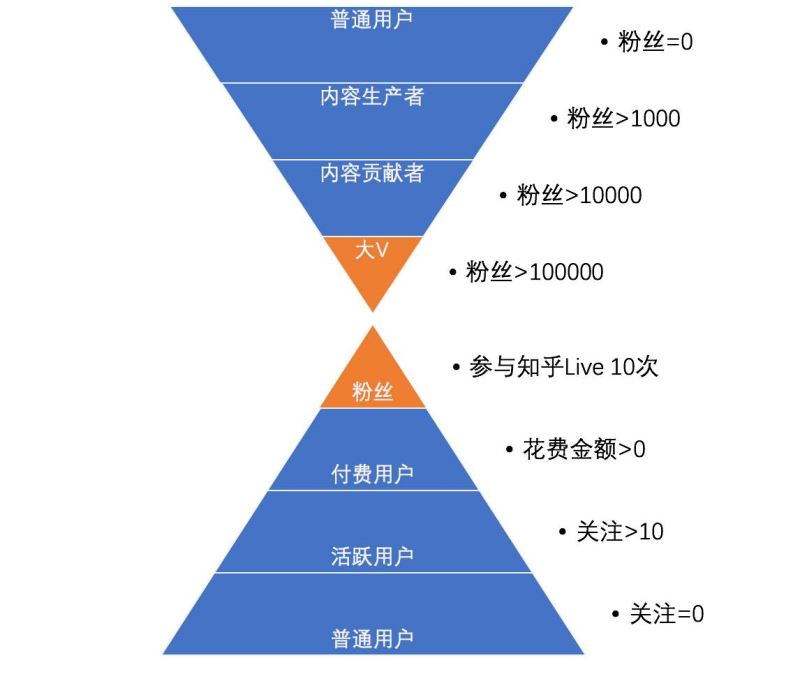
在這種結構下�,它的核心用戶,既有內容生產方向的大V����,又有消費方向的忠實粉絲,它們代表的是兩類運營策略:
內容生產方向:早期利用邀請制獲得各行業(yè)的優(yōu)秀人才��,通過運營人員維系關系���,并且鼓勵生產內容��。產品的機制也會激勵大V更好的創(chuàng)作和生產�����。
內容消費方向:則是找出普通用戶的內容興趣�,加以引導�,培養(yǎng)他們的付費習慣。增加Live����、值乎�、電子書的曝光��,設計各類優(yōu)惠券促進用戶使用���。
這類雙金字塔結構��,將內容生產者和內容消費者聚合在一起構成了整個平臺的良性循環(huán):大V創(chuàng)作內容���,吸引普通人�,普通人為內容付費,大V獲得收益���。
雙金字塔結構的用戶分層并不少見�����。以我們熟知的電子商務為例�,即有買家���,也有賣家�����。買家的運營方式已經耳熟能詳����,賣家呢��?開店教程�、賣家大學、店鋪裝修����、曝光位展示、店鋪后臺�����、各類輔助產品…運營同樣需要幫助賣家成長�����,于是賣家也可以劃分成普通賣家�、高級賣家��、大客戶、超級金主這些等級�����。
O2O是不是雙層結構��?當然是���。online是用戶,offline則是各類線下或者服務實體����,只是這些賣家更多是銷售地推和市場人員維護�����,但我們一樣可以使用分層的思想去運營�。其他還有視頻直播的網紅和群眾,微博的大V和草根�����,招聘APP的企業(yè)和員工等等�。
不同產品的形態(tài)會有差異,同一產品的不同階段�����,也可以用不同的用戶分層����。一款產品早期,用戶分層的目標是更多的用戶和KOL���,后期�����,會更貼近商業(yè)方向�����,這就需要運營設立靈活的分層了�����。
用戶分層�����,一般四五層結構就可以了�,過多的分層會變得復雜,不適合運營策略的執(zhí)行�。
用戶分群
用戶運營體系是否只有用戶分層?不完全是�。
用戶分層是上下結構,可是用戶群體并不能以結構作為完全概括����。簡單想一下吧,我們以是否付費劃出了付費用戶群體��,可是這部分群體也有差異���,有用戶一擲千金�����,有用戶高頻購買,有用戶曾經購買但是現在不買了��,這該怎么細分?
如果繼續(xù)增加層數�,條件會變得復雜,也解決不了業(yè)務需求����。
于是,我們使用水平結構的用戶分群���。將同一個分層內的群體繼續(xù)切分���,滿足更高的精細化需要。
怎么理解用戶分群����,我們拿下面的案例說明。

男女性別在以消費為核心的產品中會呈現顯著的區(qū)別�,它就是兩個相異的群體。分群的核心目標是提高運營效果�����,將運營策略的價值最大化��,在電商產品中��,區(qū)分男女很正常,但是在工具類的APP中���,或許就沒有必要性了�。
這也是我一直強調的�����,分層和分群����,都是以產品和運營目標為依據才能建立體系。
接下來是分群的實際應用�����。
RFM模型是客戶管理中的經典方法���,它用以衡量消費用戶的價值和創(chuàng)利能力�����,是一個典型的分群����。
它依托收費的三個核心指標:消費金額����、消費頻率和最近一次消費時間,以此來構建消費模型����。
消費金額Monetary:消費金額是營銷的黃金指標,二八法則指出�����,企業(yè)80%的收入來自20%的用戶���,該指標直接反應用戶的對企業(yè)利潤的貢獻�。
消費頻率Frequency:消費頻率是用戶在限定的期間內購買的次數�,最常購買的用戶,忠誠度也越高�����。
最近一次消費時間Recency:衡量用戶的流失����,消費時間越接近當前的用戶�,越容易維系與其的關系�����。1年前消費的用戶價值肯定不如一個月才消費的用戶�����。
通過這三項指標���,我們很容易構建出一個描述用戶消費水平的坐標系�����,以三個指標形成一個數據立方體:
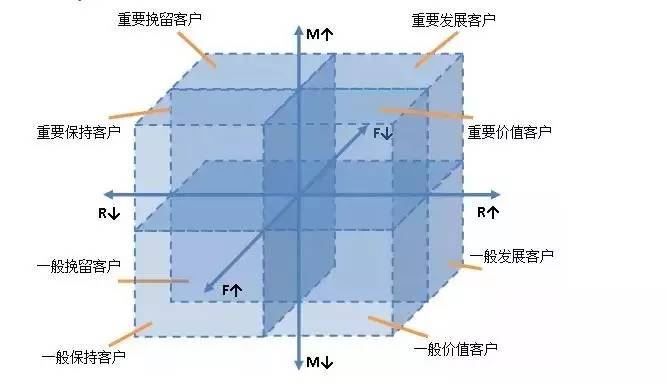
坐標系上��,三個坐標軸的兩端代表消費水平從低到高�,用戶會根據其消費水平�����,落到坐標系內���。當有足夠多的用戶數據���,我們就能以此劃分大約八個用戶群體�。
比如用戶在消費金額��、消費頻率���、最近一次消費時間中都表現優(yōu)秀,那么他就是重要價值用戶�。
如果重要價值用戶最近一次消費時間距今比較久遠,沒有再消費了��,他就變成重要挽留用戶�����。因為他曾經很有價值��,我們不希望用戶流失���,所以運營人員和市場人員可以專門針對這一類人群喚回��。
圖中不同的象限區(qū)域��,都對應不同的消費人群�����。大家是愿意簡單地視為一體去運營����,還是根據人群區(qū)別對待呢?
這就是RFM模型�����,曾經在傳統行業(yè)被頻繁應用����,而在以消費為主的運營體系中能夠移植過來為我們所用,它既是CRM系統的核心��,而是消費型用戶分群的核心����。
RFM模型的主流分群方式有兩種。
一種是建立指標�����,以指標作為劃分依據,和用戶分層差不多���。
指標的判斷和設立���,需要業(yè)務專家的經驗:什么樣的算高消費頻率,什么樣的算低����,消費多少金額算有價值�,這些都是學問。并且需要不斷修正和改進���。

上圖是一個簡化的劃分����,實際應用會更復雜����,因為指標未必有代表性。大部分收費相關的數據�,都會呈長尾分布,80%用戶都集中在低頻低金額的區(qū)間�����,20%的用戶卻又創(chuàng)造了大部分營收,這是劃分的難點�。
指標一般用描述性統計的分位數,以中位數����、第一四分位數、第三四分位數等劃分�����。
另外一種是用算法�,通過數據挖掘建立用戶分群,不需要人工劃分��。最常見的算法叫KMeans聚類算法����,核心思想是「物以類聚,人以群分」��。
我們以網上某公司的數據進行Python建模��,首先無量綱化(z-score)處理��,并且清洗掉異常極值。

上圖的三列數據是經過標準化后的用戶消費數據�。值越接近0,說明離平均水平越近�����。r值因為是最近一次消費時間�,所以值越小,說明時間越接近�,值越大,說明消費越久遠���。
通過RFM三個指標(在機器學習中叫做特征)�,先建立可視化的散點圖���。下圖是最近一次收費R和收費金額M的散點圖。每一個點都代表著一位用戶的收費相關數據���。

散點圖上暫時看不出用戶分群的規(guī)律�����,只能初步判斷�,大部分的數據呈集中趨勢。
既然KMeans算法的核心思想是「物以類聚��,人以群分」,它就是以距離作為目標函數���。簡而言之��,在距離上越接近的兩個用戶�,其相似的可能性也越大�,于是KMeans就把相似的群體找出來�����,叫做簇�����。簇與簇之間的距離越大����,用戶群體間越獨立,這叫群分��;簇內的距離越緊湊��,說明用戶們越相似,這叫類聚�。
通過圖表說話:
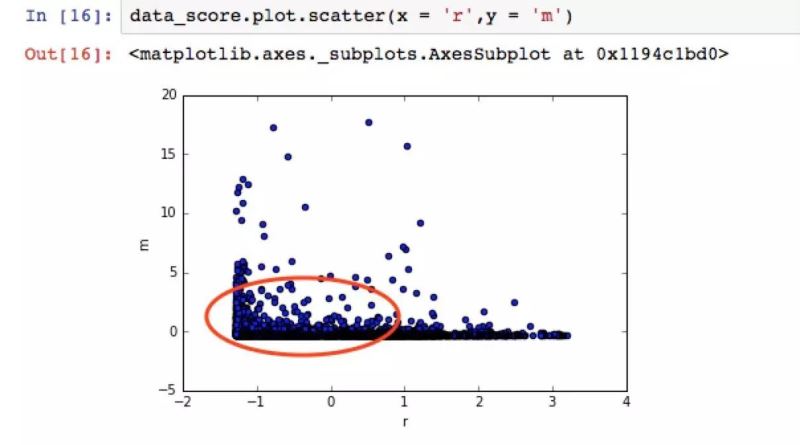
紅圈標出的這些用戶����,更有可能相似�,屬于同一個用戶群體。因為他們在R和M這兩個指標上�,數據接近,都處于消費金額較低����,且近期有消費的人群。
至于是不是���,讓算法解決吧�����,具體的算法原理和過程就不演示了�。我們假設能劃分出五類用戶群體,然后看下這些人群是什么樣的���。

上圖的不同顏色,就是算法計算出的用戶群體�����。
紅色用戶群體:代表的是高消費金額,因為數量稀少��,所以在最近一次消費時間上沒有明顯區(qū)分����,不過并不久遠。這些都是產品的爸爸和金主��。
綠色用戶群體:代表的是有流失傾向的用戶,這些用戶消費金額不太多��,運營可以采取適當的挽回策略。
紫色用戶群體:代表的是近期消費�����,消費金額較少的用戶,運營需要挖掘他們的價值���,去發(fā)展和培養(yǎng)��。
青色和藍色似乎不能明顯區(qū)分。那我們改一下散點圖的維度呢���?

改用指標R和F后,則是另外一種視角���。青色用戶群體比藍色用戶群體有過更多的消費次數����,藍色用戶的消費頻率比較差�����,更需要激勵����。紫色用戶群體擁有相當高的消費頻率。
到此��,用戶群體已經明顯區(qū)分���,大家是否能準確概述這些用戶的特點了呢?雖然從數據分布上�,長尾形態(tài)會一定程度影響可讀性����,但運營還是能針對不同群體作出相應的運營手段。
通過散點圖矩陣觀察最終的結果 (圖片可能清晰度不佳):
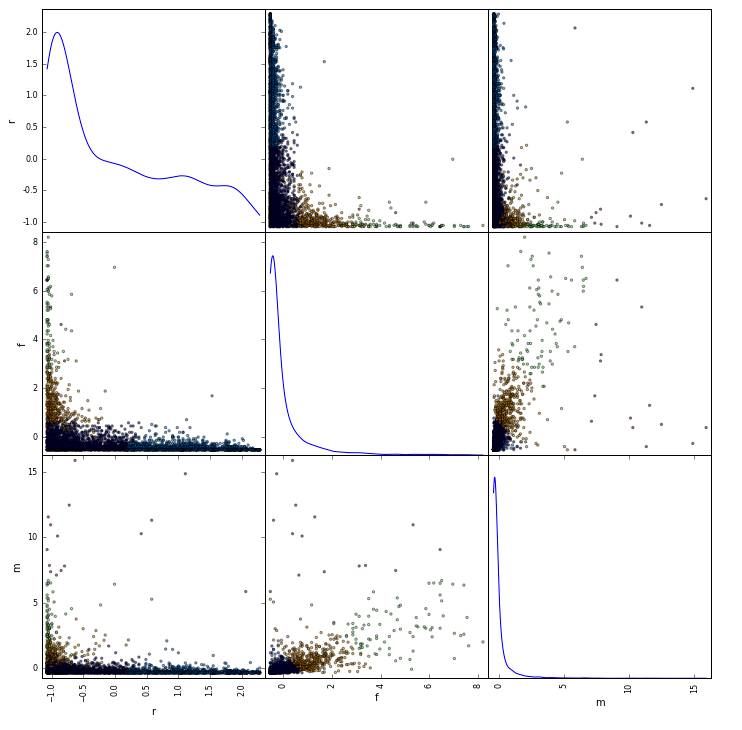
以上就是RFM模型的內容��。它能動態(tài)的提供用戶的消費輪廓,給市場����、銷售���、產品和運營人員提供精細化運營的依據�����。這也是數據挖掘在用戶運營的應用之一���,大家要了解。
怎么劃分群體是一門學問����,劃分的群體少了����,區(qū)分度不明顯;劃分的多了��,則沒有業(yè)務價值,二十幾個群體你怎么去運營�?群體數量�,是要在數據和業(yè)務間取得平衡���。
總而言之���,分群的方法�,一類是通過指標和屬性人工的劃分出用戶群體����。另外一類是通過數據挖掘,給結果賦予業(yè)務意義�。反正最終的目的是提高運營效果和價值�����。
我們可以用RFM模型���,試著將思維更開闊一下�,能不能玩出新花樣?完全可以嘗試�。
金融:投資金額、投資頻率��、最近一次投資時間;
直播:觀看直播時長�����、最近一次觀看時間、打賞金額�����;
內容:評論次數、評論字數��、評論被點贊數�����;
網站:登錄次數�����、登錄時長、最近一次登錄時間�;
游戲:等級�����、游戲時長�����、游戲充值金額�����。
這些是我簡單列舉的參考�,未必準確�,作為大家參考的他山之石���。不同產品的分群策略也不一樣,比如酒店產品����,住宿不是一個固態(tài)的需求����,是否需要加入時間的維度呢?也許住宿條件會更好分群�����。
需要注意的是�����,群體數量并不固定�,可以是兩個���,也可以是四個�����,具體就看業(yè)務需求,主要是能囊括大部分用戶���。只是別太多���,一來復雜,二來KMeans聚類在多特征的表現不算好�����。
通過用戶分層和用戶分群,想必大家已經了解了用戶運營體系的基石�。用戶分層,是基于大方向的劃分����,你希望用戶朝什么核心目標努力,而用戶分群�����,則是將他們切分更細的粒度提高效果�����。兩者是相輔相成的�。
如果用戶大到一定量級�,分層和分群就未必是好的方法��,因為用戶群的屬性粒度特征隨著產品進一步擴大�����,不論怎么細分都難以滿足用戶的復雜性���,常見于各類平臺型產品�。這時候需要引入用戶畫像(UserProfile)體系�,此時的用戶分層和分群�,都只是畫像的一部分了�����。
