目錄
- 基于內(nèi)容的推薦系統(tǒng)
- 基于協(xié)同過濾的推薦系統(tǒng)
- (1)基于item的協(xié)同過濾
- (2)基于用戶的協(xié)同過濾
基于內(nèi)容的推薦系統(tǒng)
根據(jù)每部電影的內(nèi)容以及用戶已經(jīng)評過分的電影來判斷每個用戶對每部電影的喜好程度���,從而預測每個用戶對沒有看過的電影的評分��。
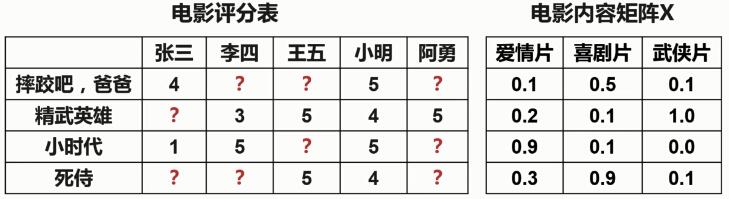
電影內(nèi)容矩陣X * 用戶喜好矩陣θ = 電影評分表
那么����,用戶喜好矩陣θ(用戶對于每種不同類型電影的喜好程度)如何求解呢?
用戶喜好矩陣θ的代價函數(shù):
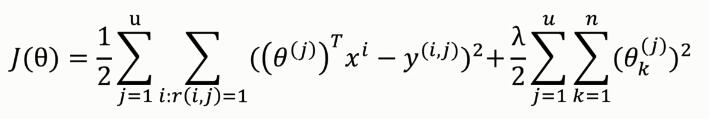
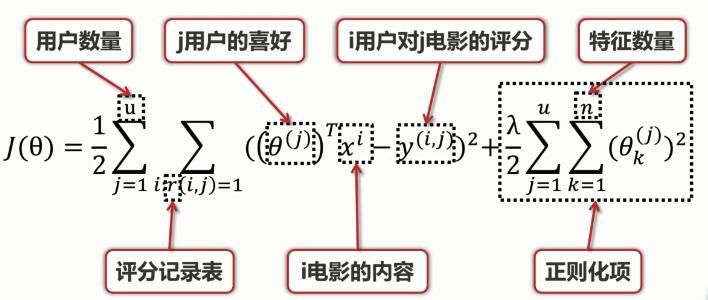
其中����,正則化項為防止過擬合。
(1)不存在商品冷啟動問題
(2)可以明確告訴用戶推薦的商品包含哪些屬性
(1)需要對內(nèi)容進行透徹的分析
(2)很少能給用戶帶來驚喜
(3)存在用戶冷啟動的問題
基于協(xié)同過濾的推薦系統(tǒng)
根據(jù)電影評分表和用戶喜好矩陣θ��,來求得電影內(nèi)容矩陣X���。然后����,將電影內(nèi)容矩陣X與用戶喜好矩陣θ相乘���,這樣就得到了一個完整的電影評分表�。
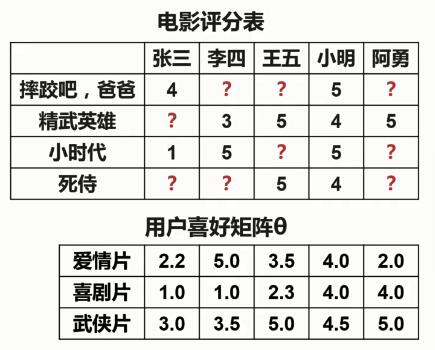
所以�,基于協(xié)同過濾的電影推薦就是根據(jù)每個用戶對于每種電影類型的喜好程度以及用戶已經(jīng)評過分的電影來推斷每部電影的內(nèi)容����,從而預測每個用戶對沒有看過的電影的評分。
那么��,如何求解電影內(nèi)容矩陣X呢?
電影內(nèi)容矩陣X的代價函數(shù):
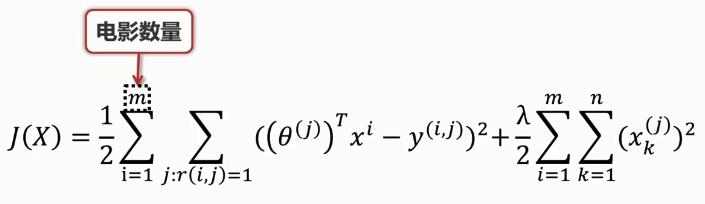
用戶喜好矩陣X的獲?���。?/p>
(1)通過在線問卷調(diào)查來獲取用戶對電影的評價,但并不是所有的用戶都會填寫����,就算填寫了,也不一定全部是正確信息�����;
(2)通過一種更高效的方式來同時求解電影內(nèi)容矩陣X和用戶喜好矩陣θ.
通過前面���,可以看到電影內(nèi)容矩陣X和用戶喜好矩陣θ�,它們的第一項是相同的��,因此��,我們可以將這兩個公式合并為一個公式來同時求解X與θ�,這種方法的好處就是只用搜集用戶對電影的評分。
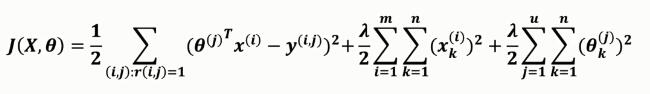
目標是最小化這個代價函數(shù)����,隨機初始化X和θ�,通過梯度下降法或其他優(yōu)化算法求解�����。
(1)基于item的協(xié)同過濾
先計算商品之間的相似度�,然后根據(jù)商品之間的相似度來向用戶進行推薦,如:用戶購買了硬盤���,則很有可能向用戶推薦u盤��,因為硬盤和u盤具有相似性�。
在基于item的協(xié)同過濾中�,只需要用戶對商品的評分,首先需要計算商品之間的相似度���。
如何度量商品之間的相似度�?
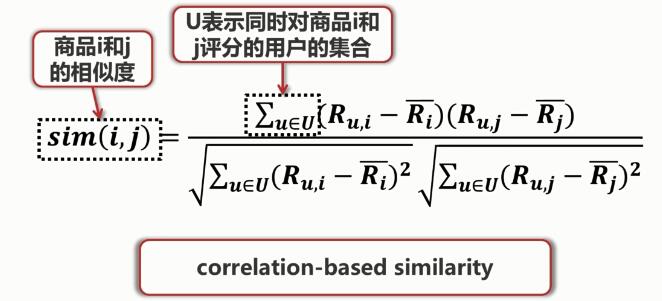
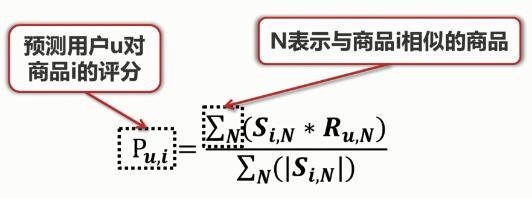
計算出商品之間的相似度之后����, 我們就能夠預測用戶對商品的評分���。
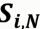 :商品i 與其他商品的相似度
:商品i 與其他商品的相似度
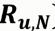 :用戶u對其他商品的評分
:用戶u對其他商品的評分
分母:與商品 i 相似的商品的相似度的總和
表達的是:根據(jù)用戶u對其他和商品 i 相似的商品的評分來推斷用戶對商品 i 的評分�����。 當求出用戶u對所有商品的預測評分后��,將其進行排序�,選擇得分最高的商品推薦給用戶。
(2)基于用戶的協(xié)同過濾
基本思想:假設我們要對用戶A進行推薦�����,首先要找到與用戶相似的其他用戶�,看其他用戶都購買過其他商品,把其他用戶購買的商品推薦給用戶A�。
這時就需要度量用戶之間的相似度,與基于item的協(xié)同過濾類似:
 :用戶u對商品 i 的評分
:用戶u對商品 i 的評分
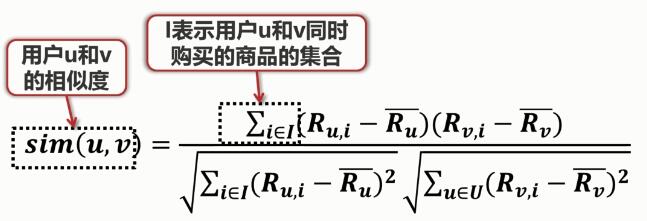
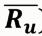 :用戶u對這些商品評分的平均值
:用戶u對這些商品評分的平均值
計算了用戶之間的相似度之后就可以預測用戶對商品的評分��。
商品評分公式:
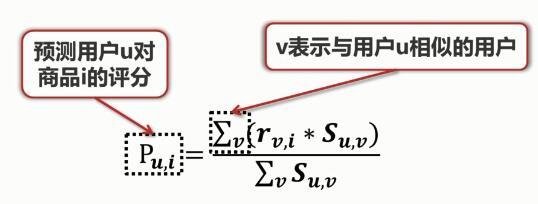
公式表示:根據(jù)與用戶u相似的其他用戶對商品i 的評分來推斷用戶u對商品i 的評分�����。 當求出用戶u對所有商品的預測評分后����,將其進行排序,選擇得分最高的幾個商品推薦給用戶���。
- 基于協(xié)同過濾推薦系統(tǒng)的優(yōu)點:
(1)能夠根據(jù)各個用戶的歷史信息推斷出商品的質(zhì)量
(2)不需要對商品有任何專業(yè)領域的知識
(1)冷啟動問題
(2)gray sheep
(3)協(xié)同過濾的復雜度會隨著商品數(shù)量和用戶數(shù)量的增加而增加
(4)同義詞的影響
(5)shilling attack:對競爭對手的商品專門打低分���,對自己的商品打高分
日常生活中��,我們每個人其實都直接或者間接接觸過推薦系統(tǒng)��,也都享受過推薦系統(tǒng)帶來的生活上便利���。關于推薦系統(tǒng)的介紹就到這里,希望大家以后多多支持腳本之家!
您可能感興趣的文章:- 不到40行代碼用Python實現(xiàn)一個簡單的推薦系統(tǒng)
- 如何用Python來搭建一個簡單的推薦系統(tǒng)
- Python用戶推薦系統(tǒng)曼哈頓算法實現(xiàn)完整代碼
- Python基于機器學習方法實現(xiàn)的電影推薦系統(tǒng)實例詳解
