作者簡介
雷蕾�,攜程度假研發(fā)部資深算法工程師�,負責智能客服算法工作�。
鞠劍勛,攜程度假研發(fā)部算法經理���,負責智能客服���、知識圖譜��、NLP算法等工作�。
隨著人工智能的發(fā)展��,人機交互技術愈發(fā)成熟,應用場景也越來越多�����。智能客服是人機交互在客服領域的一個應用,服務于客人以及相關的客服人員。本文將介紹智能客服在旅游場景下的主要技術和應用。
當前度假的智能客服主要用于C端(客戶端)面向客人,以及客服端輔助客服的兩個角色�。
面向客服端的是智能客服助手�,用于對話窗口的側邊欄�,提示客服人員當前客人問題的答案�����,客服人員可視情況來采納;而面向C端的智能客服則是直接服務于客人���,回答客人問題����。
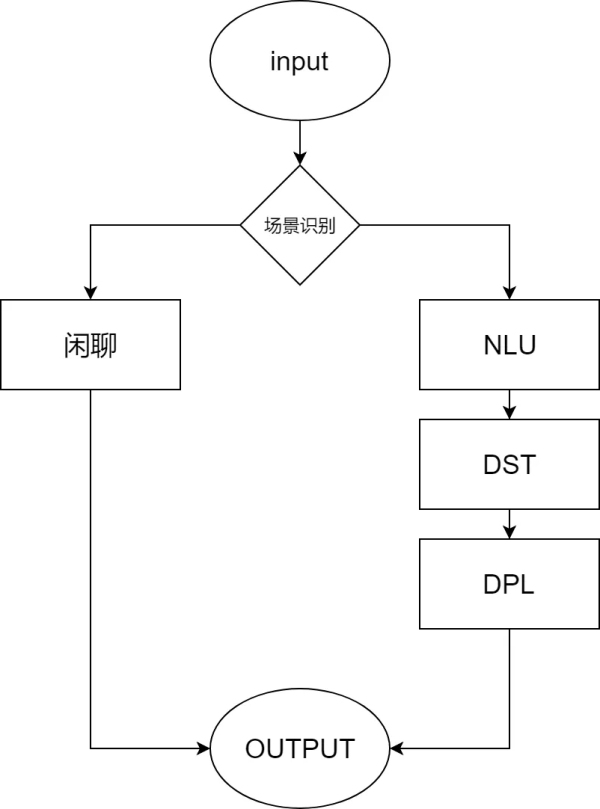
智能客服又分為單輪問答的QABot和多輪對話的TaskBot�,在攜程的旅游場景下,以多輪對話的TaskBot居多�。一般多輪對話的智能客服系統(tǒng)會切分為以下幾個模塊:客人的問題(Query)進來后首先經過NLU模塊抽象化為客人的意圖(intent)以及關鍵信息槽位(slot),意圖及槽位傳給DM模塊后�����,經過DST�、DPL���、NLG模塊返回答案���。
- NLU(Nature Language Understand自然語言理解)����,通過模型或規(guī)則的方式獲取客人的意圖和槽位�����;
- DST(Dialog State Tracking對話狀態(tài)追蹤)存儲對話狀態(tài)�,包括每一輪對話的意圖以及已經抽取到的槽位信息、歷史機器人的行為��;
- DPL(Dialogue Policy Learning對話策略選?�。?�,DPL根據(jù)DST傳輸?shù)膬热輿Q策機器人在該輪的行為����;
一�����、NLU
NLU模塊基礎功能是獲取客人的問題的意圖及槽位信息��,在業(yè)務比較復雜的場景�,相對應客人可能問的問題維度也會很復雜��。如果答案涉及的條件很多的情況,往往單輪的QA無法很好的解決客人問題����。因此在度假業(yè)務的場景下�,多輪次的TaskBot會占大多數(shù)��。
1.1錯別字糾正
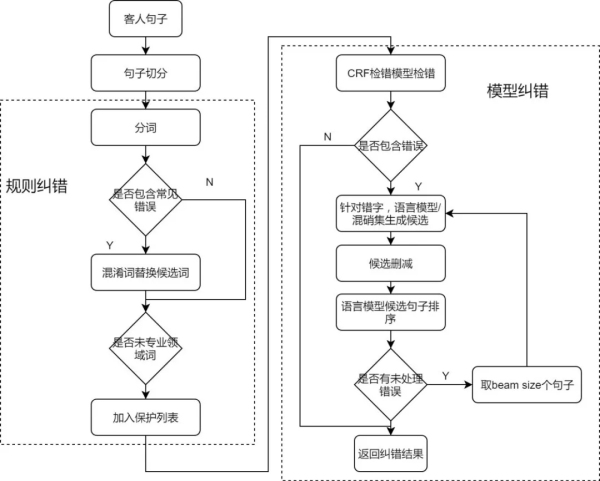
原始語句中難免會出現(xiàn)錯字���,錯字可能會改變最終輸出的答案�。在識別意圖之前首先通過糾錯模塊對錯別字進行糾正�����。
兼容速度和準確率考慮,糾正分為規(guī)則部分和模型部分����,度假業(yè)務中涉及到的地點比較多,在規(guī)則部分就能夠覆蓋大部分錯別字的情況���。模型部分首先會經過一個CRF模型輸出字級別存在錯誤的可能性�����,生成候選集后���,通過語言模型計算候選集句子的置信度,重排序得到最終糾正的結果�����。
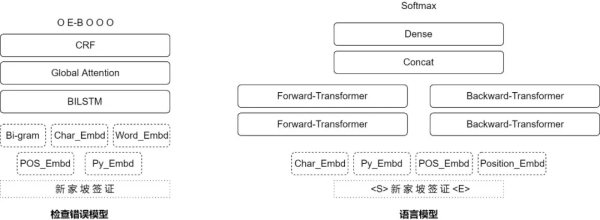
- 檢查錯誤模型����,主要使用了五種特征向量連接后進入Bi-LSTM-ATT-CRF模型,得到對每個字是否錯誤的判斷����。
- 語言模型計算候選集替換為該字的情況在語言模型內的得分��,文本轉為特征向量后經兩層向前和后向前的Transformer���,最后全連接計算softmax。
1.2意圖識別
意圖實質上是對客人問題的抽象化����,比如常見的客人問及這個產品多少錢�?,可轉換為詢問價格意圖��。而在直接服務客人的C端上����,對回答答案準確率有較高的要求,高質量的服務背后首先是高準確率��,而且通常在設計意圖前期會存在意圖訓練語料不足的問題��,因此一個高準確率并且弱監(jiān)督的意圖識別模型非常重要��。
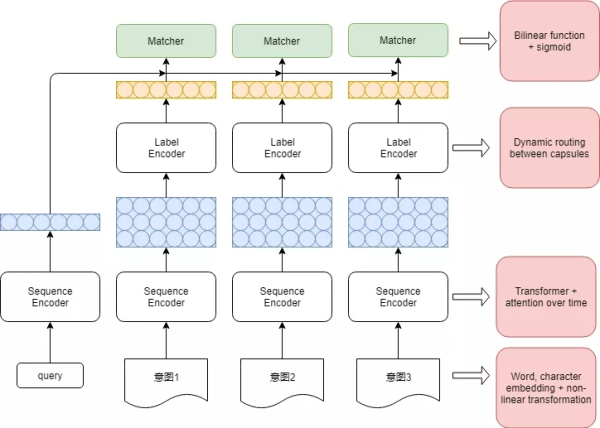
意圖識別模型
意圖識別模型整體采用上圖的類似matchingnetwork框架�,每個意圖會有一個類別表示,新的query經計算獲得其句向量���,通過計算和每個類別的相似度得到該客人問題的意圖�����。
當前的意圖識別模型�����,相比于傳統(tǒng)的文本分類模型��,準確率更高�,標注量更少,同時更方便遷移到多意圖的情景��。
在訓練階段�����,共有已知C個類別�����,每個類別N個樣本����,語句經特征向量經過Bi-LSTM層后再通過Transformer-Attention把一句話映射為一條向量�����,最后經膠囊網(wǎng)絡獲得每個類別的類別向量�。每個訓練語句得到句向量后�����,再通過Bilinear-Function-Sigmoid計算與的相似度得分����,最后采用二分類的對數(shù)似然損失函數(shù)計算損失����。
模糊意圖的處理
我們研究表明,客人在和機器人對話及與人對話的時候一些行為習慣是不同的���。在面對機器人的時候�,客人傾向于把機器人作為一個搜索引擎�,常常輸入關鍵詞來獲得回答,但關鍵詞的信息不完整���,通過模型或模板都無法返回切合的意圖���。針對于此����,我們采用了聯(lián)想問和猜你想問的功能來引導客人的提問方式�。
客人在聊天輸入欄輸入問題的同時,顯示相關的一些問題以供客人點選�����,由于是實時顯示��,對速度的要求較高����,這里我們使用的是檢索算法計算文本相似度。
我們會為每一個意圖人工設置一些用戶常問問題����,當用戶輸入的時候,我們會用文本相似度的算法���,算出和用戶輸入最接近的三個常問問題����,提示給用戶供其選擇。
對于猜你想問功能���,主要是處理問句過短的語義不明的情況�。舉個例子�,在簽證領域,客人會輸入照片���,而和照片相關的意圖有是否需要照片�����、照片要求�、照片尺寸大小等等能夠涉及到的十幾個意圖����。在觸發(fā)猜你想問后��,會返回4個最關聯(lián)的問題供客人點選���。
在使用猜你想問和聯(lián)想問的機制后�,可以引導部分客人的用戶輸入習慣�,提升單輪次下信息輸入的完整性及純凈度�。
1.3發(fā)現(xiàn)新意圖
一個新業(yè)務線設計意圖的時候���,不可能把所有會出現(xiàn)的意圖都理清楚�,而是循序漸進��,逐步增加��。業(yè)務人員本身對業(yè)務的熟悉程度可提供新業(yè)務線的意圖大框架����,在小細節(jié)上難免存在漏缺,或是因為實時政策的變化產生的新問題�。
比如說,在今年六月份大陸禁止發(fā)放臺灣自由行簽證���,這段時間就新產生了很多類似于已辦的臺灣簽證是否還可使用���、是否還能辦臺灣G簽證等這些新的客戶問題。
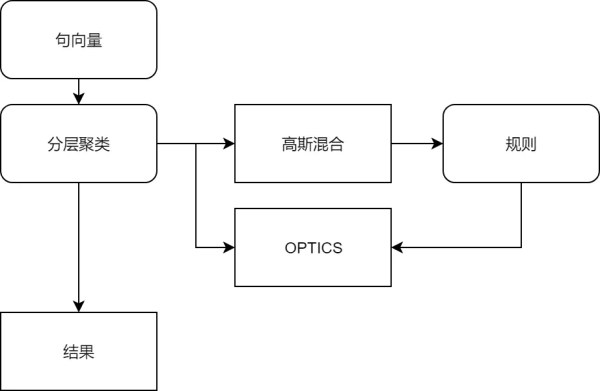
層次聚類
我們采用的是對原始問題聚類的方法����,把相似句聚集在一起。經過數(shù)據(jù)預處理后����,生成句向量����,第一層使用高斯混合得到一個初步的聚類結果�,再通過規(guī)則判斷是否需要再進行一次聚類,隨后在第二層使用OPTICS聚類�。
在用算法發(fā)現(xiàn)意圖后,并不會即刻投入使用��,而是業(yè)務做重審確定�����,整體上新意圖的定位在于輔助業(yè)務對意圖體系的完善����。
1.4槽位抽取
在TaskBot中,槽位信息抽取主要是服務于檢索答案�。比如簽證一個常見問題辦簽條件���,需要確定客人的辦簽國家����、戶口所在地、居住地等信息后才能給出最終回答����。
有時客人的問題中直接會涉及相關槽位,目前槽位抽取采用的是規(guī)則+模型的方式�。在實際應用中,規(guī)則能夠覆蓋70%的情況����,剩下的則由模型來負責。
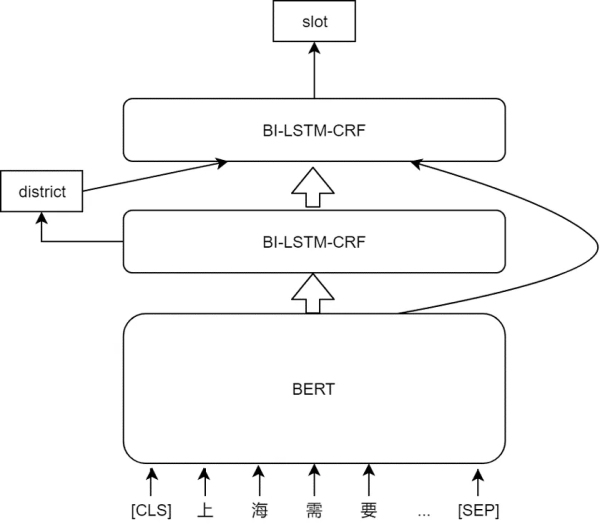
在度假業(yè)務里需抽取的槽位詞有一個明顯的層次關系��,比如地點-送簽地��、地點-辦簽國家�����、職業(yè)-在職��、職業(yè)-自由職業(yè)等����,在模型的設計上會先抽第一層,第二層才是對最終結果的二級識別,通過多任務的學習�����,實際上每一層的任務是在對特征進行自動抽取�。
大型的語言模型,比如說今年大熱的BERT�,在很多NLP任務中大放光彩。在這個詞槽抽取任務中����,語句中會先經過BERT得到字向量后,第一層經Bi-LSTM-CRF模型得到第一類的結果以及Bi-LSTM的編碼結果���,會映射為對應的類向量���,經、��、連接后進入第二層Bi-LSTM-CRF后得到最終的詞槽�����。在加入語言模型后��,對于語料比較少以及地點比較多的情況提升會比較大�,尤其是一些語料中沒出現(xiàn)過的地點,加入語言模型后也能識別出來��。
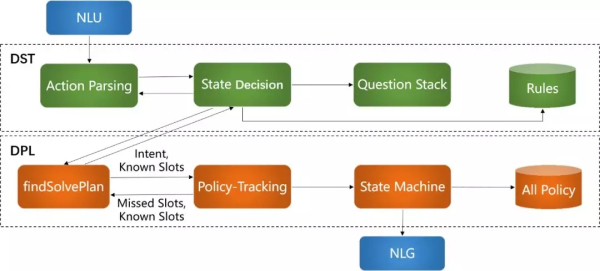
二�、對話管理系統(tǒng)
對話管理系統(tǒng)模塊主要負責對話狀態(tài)追蹤DST(每輪意圖、槽位的存儲)�����、對話策略選取DPL(反問或給出答案)��、答案生成NLG����。在這部分接收NLU識別的意圖和槽位結果,DST把對話狀態(tài)信息發(fā)送給DPL���,DPL根據(jù)知識庫中的規(guī)則返回機器人在下一輪的決策(回答問題�����、反問或其它操作)�。
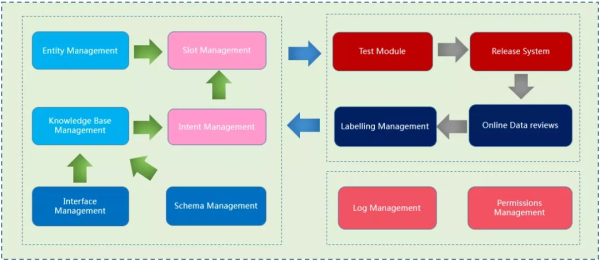
三�����、智能客服平臺
在整體上,智能客服業(yè)務和技術的部分是解耦的���。業(yè)務相關信息的設定和操作都是通過智能客服平臺�,包括不同業(yè)務線的意圖和詞槽的設定�����、答案配置�、數(shù)據(jù)審核、測試��、標注等����。新建一條業(yè)務線的智能客服應用,只需要在平臺上新建項目�����,輸入設定的意圖���、對應的語料����、必要的槽位和對應的答案���。
此外����,平臺上的答案配置也很靈活����,可以是固定回答,可以是知識圖譜的schema���,可以是外部的接口���,或是隨不同詞槽設定的回復等等。
四����、結語
以上是度假人機交互的主要技術和成果,目前我們已經完成了一個智能客服項目落地的閉環(huán)�,其中還有很多內容可以持續(xù)完善,比如多輪的意圖識別�����、更多主動對話的探索等等。
未來的智能客服機器人將往多模態(tài)和多語言方向發(fā)展����,支持語音和圖像等模態(tài)的解析,支持英法日韓等多國的語言�。智能客服還將提供主動服務模式、人機協(xié)同模式����、群聊功能等多種模式。此外�,采用大規(guī)模挖掘和生產的方式降低人工標注成本也是未來的主要方向之一。