2019年3月25日,小i機器人聯合香港科技大學共同成立了“機器學習和認知推理聯合實驗室”���,這是小i機器人與香港學術機構共同開展的首個科研項目�����,也是小i機器人構建全球研發(fā)體系的重要一環(huán)���。聯合實驗室的成立��,標志著小i機器人的自主創(chuàng)新力和國際影響力得到了進一步提升��。
“機器學習和認知推理聯合實驗室”成立以來,雙方在高階認知推理系統(tǒng)��、機器學習和自然語言處理等相關理論及技術研究上�����,展開了深入合作并實現了多向突破��,產出的多篇優(yōu)質論文也多次登陸ACL���、AAAI���、AAMAS等國際頂級會議。
以下為香港科技大學-小i機器人聯合實驗室入選國際頂級會議的代表性論文���。
研究方向:問答系統(tǒng)會話生成
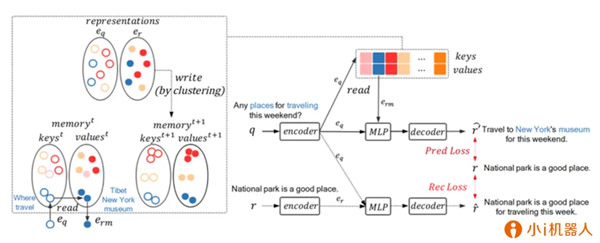
代表性論文:《學習如何抽象:一種記憶增強的會話回復生成》
入選會議:ACL2019
現有的會話回復生成模型存在生成的回復多樣性差�����、信息量不足等一些問題����。一些研究人員嘗試利用檢索系統(tǒng)去增強生成模型的效果����,但是該方法受限于檢索系統(tǒng)的質量���。在本文中,我們提出了一種記憶增強的生成模型���,由記憶模塊和生成模塊組成�,它可以對訓練語料進行抽象��,并且把抽象出來的有用的信息存儲在記憶模塊中��,以便輔助生成模型去生成回復����。具體來說,我們的模型會先對用戶輸入(query)-回復(response)的句對做聚類��,接著抽取出每個類的共性�����,然后讓生成模型學習如何利用抽出的共性信息�����。與普通檢索增強模型相比���,我們的模型改進了回復生成的質量��,相關性和信息完備性����。
研究方向:對話系統(tǒng)
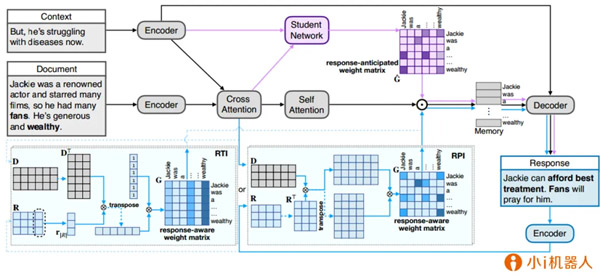
代表性論文:《基于回復預期記憶的隨需知識集成機制在回復中的應用》
入選會議:ACL 2020
眾所周知�,神經對話模型的響應雖然正確,但缺乏足夠的內容和信息��。通過閱讀進行對話(CbR)可以大大增強信息量���,其中針對給定的外部文本進行對話���,圍繞CbR任務,我們提出了一種新穎的預期-回復文本存儲�,用來利用和記住在回復生成的過程中重要的文本信息。我們通過教-學框架構造了預期的記憶����。向教師模塊提供了外部文本,上下文和真實的回復�����,教師請求回復并學習回復-意識權重矩陣;學生模塊根據外部文本��,上下文和教師模塊的輸出�,學習如何預估教師模型中的權重矩陣,并構建預期的響應文本記憶�。我們通過自動和人工評估驗證了我們的模型,實驗結果表明我們的模型獲得了CbR任務的最高性能�����。
研究方向:機器學習注意力機制
代表性論文:《并非所有的注意力都需要:序列數據的門控注意力網絡》
入選會議:AAAI 2020
近年來�����,動態(tài)網絡配置受到越來越多的關注��,它是一種具有動態(tài)連接的卷積機制神經網絡�����,與注意力機制不同����,它可以一次選擇性地激活一部分網絡����。在本文中���,我們提出了一種用于序列數據的稱為門控注意力網絡(GA-Net)的新方法。GA-Net使用輔助網絡動態(tài)選擇要參加的元素子集�����,并計算注意力權重以聚合所選元素�����。避免了對不必要元素的大量計算��,并使模型可以關注序列的重要部分����。它結合了兩個與輸入有關的動態(tài)機制,注意力機制和動態(tài)網絡配置��,并具有動態(tài)稀疏的注意力結構�����。實驗表明,提出的方法在IMDB�����、SST-1等文本分類任務上持續(xù)獲得最佳結果��,同時減少需求計算并獲得更好的可解釋性�����。
研究方向:多智能體的決策和博弈
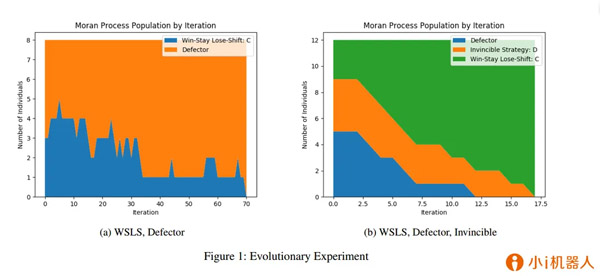
代表性論文:《平均收益重復囚徒困境的無敵策略》
入選會議:AAAI 2020
重復囚徒困境(IPD)是研究理性多智能體的長期行為的著名基準�����。針對這個問題學術界已經研究了許多眾所周知的策略����,從簡單的針鋒相對(TFT)到更復雜的策略,例如Press和Dyson最近研究的零行列式和勒索策略�。在本文中,我們考慮了所謂的無敵策略�,無敵策略有以下幾個特點,首先�����,他們有一個非常清晰和直觀的定義-永遠不會輸掉一場比賽�����。其次,它們的特征十分簡單-可以被三個簡單條件所表示�。第三��,它們與諸如Press和Dyson的勒索策略以及Akin的good策略等其他經過深思熟慮的策略密切相關�。最后,從實驗中我們發(fā)現���,一些既不勒索也不合作的無敵策略也可以像TFT一樣發(fā)揮作用��。我們的策略為重復博弈�����,尤其是IPD的研究做出了貢獻�����。
研究方向:多智能體的決策和博弈
代表性論文:《重復囚徒困境的無敵策略》
入選會議:AAMAS 2019
重復囚徒困境是研究多智能體博弈的經典經濟學模型��。各個領域的學者廣泛地使用這一模型�����,來研究合作是如何在多智能體演化過程中產生的�����。早在1981年��,Axelrod組織了基于這一模型的策略競賽��,“針鋒相對”策略獲得了冠軍��,對后來的研究產生的深遠的影響�����。2012年以來��,隨著“零行列式策略”的提出����,又涌現出許多具有特殊數學性質的策略。受到我們最初觀察的啟發(fā)�����,沒有任何策略可以擊敗勒索策略,我們繼續(xù)研究所有這類立于不敗之地的策略�����。我們的主要技術成果是�����,此類策略可以被三種簡單條件所表示���,還將此類策略與其他策略相關聯,并考慮了它們在結合時顯示的作用�。