語音識別是將語音即時的轉換成文字�,而這音源是源自麥克風或是其它的音訊來源,將其音訊傳送到伺服器運算處理或是本地運算辨識����。而當將音訊傳送到伺服器時,可得到回傳的辨識結果����,例如文字或是解析音訊的意圖���;例如“臺北市的天氣“等等。而當應用程式回應使用者時���,此時需要將文字轉換成語音���。
在將語音串流進入辨識前,需要做雜音抑制處理����,如果這部分沒有處理好,會降低系統(tǒng)的辨識率�;例如在安靜的環(huán)境下,辨識率是很高的�,而在雜音較多的地方,是不是也能確實做到語音識別呢�?
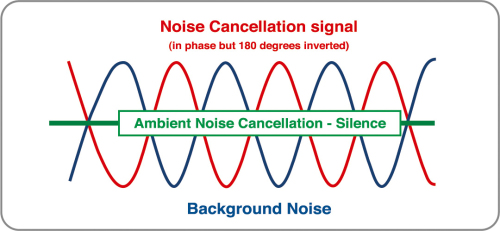
如何的保持聲音的品質呢?將噪音消除��,可以透過降噪的處理方式����,如下圖:
在降噪的技術里有Feedback ANC及Feed-Forward ANC等等���,而這噪音的調校又會跟本身的機構、麥克風的位置���、方向是息息相關,缺一不可�。
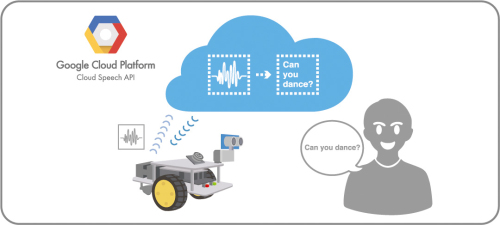
當正確取得聲音串流時,后續(xù)就是選擇語音的辨識伺服器�����,以Google所提供的平臺為例�����,它提供了一系列的Cloud Speech API��,讓使用者可以輕松的應用語音識別的控制���。
而將聲音串流錄制并傳送到伺服器及進行本地的語音回應輸出�����、控制����;這時你需要一個強而有力的控制平臺,想當然爾���,大多數(shù)會選擇Linux平臺�,可以快速的取得相關的資源并連結網(wǎng)路�����,所以在挑選Linux開發(fā)平臺時�����,最重要的要確認平臺是否有持續(xù)支援Linux main line����,這是一個非常重要的指標,以確保你的Linux平臺是可以持續(xù)的支援新的Linux版本�。
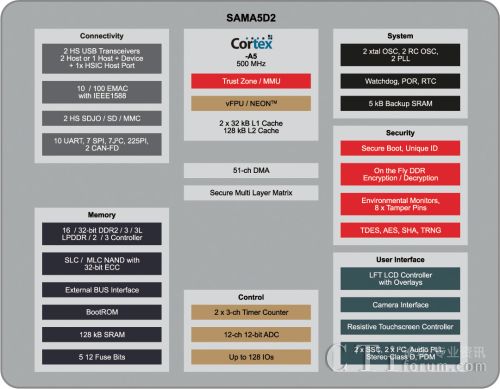
Microchip的產品SAMA5D2系列提供Linux開發(fā)平臺及及豐富周邊控制模組,讓你可以快速的建立產品應用����。而為了縮短使用者的開發(fā)時間���,也提供SoM的開發(fā)平臺,這可以大大的降低使用者的開發(fā)時間及硬體的設計難度�����。
未來全球語音識別市場將會變得更加多樣化���,同時軟體準確度上會有大幅提升�。
在醫(yī)療領域的應用:
不僅是簡單的通過智慧手表追蹤運動情況和心率���,還有直接根據(jù)人的身體狀況匹配相應的服務如合適的餐廳或食物等,當然這些大多是基于穿戴式設備的����。另外他們還考慮到更多場景,諸如緊急語音求助�����,醫(yī)患對話存檔����,呼叫中心的對話聽寫等。由于醫(yī)療領域詞匯庫專業(yè)性強演變性弱,只要建立完整的數(shù)據(jù)庫���,就可以做到對疾病名稱���、藥品名稱相對精確的識別。
在智慧車載的應用:
行車安全問題上一直聚焦了很多目光�����,去年有人曾經(jīng)設計出一個車載屏幕�����,可以利用多指的簡單手勢解決司機操作觸控螢幕過度分散注意力的問題��。通過將車載平臺與手機連接���,可以幫用戶實現(xiàn)語音控制GPS導航����,訊息收發(fā)��,電話接打����,社群網(wǎng)路更新等等�����。