我們知道搜索引擎的產(chǎn)品線很長,多個產(chǎn)品之間總不可能完全完美地配合����,因此在robots.txt的限制收錄那里就產(chǎn)生了一個可以被利用的漏洞�。
原理分析(以搜狗為例)
搜狗針對各個搜索引擎,對搜索結果頁面進行了屏蔽處理���。其中“/sogou?”��、“/web?”等路徑均是結果頁面的路徑���,那么�����,會不會有這樣一種情況���?搜狗存在其他的搜索結果頁面路徑,但是在robots.txt中卻沒有申明屏蔽��?為了驗證這一猜想���,我們到百度中搜索搜狗�����。
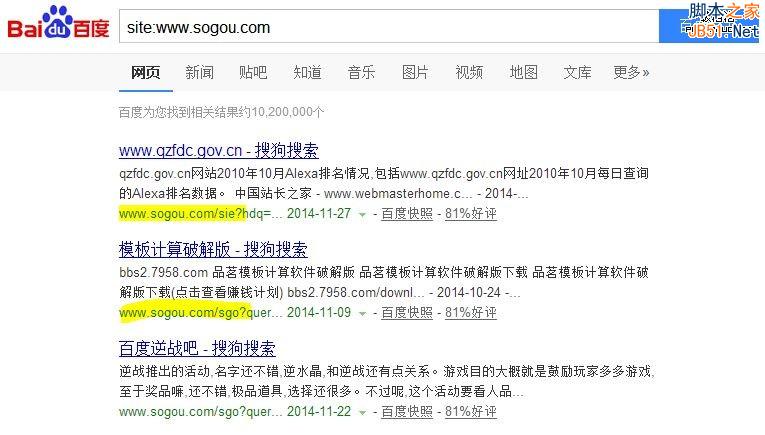
我們可以看到其中“/sie?”�����、“/sgo?”均為搜狗搜索結果頁面的路徑�����,但是在robots.txt文件中卻沒有被申明屏蔽��!即是說這樣路徑的頁面時允許被搜索引擎收錄�����,如果這樣的頁面的搜索結果全部都是自己的網(wǎng)站呢����?那么就實現(xiàn)了讓搜索引擎給自己網(wǎng)站做外鏈的效果�����!
那么問題來了���?如果讓搜索結果全部都是自己的站點呢��?很自然地就會想到站內搜索��!具體尋找站內搜索參數(shù)的方式請自行搜索相關資料����,此處直接說明結果:搜狗的站內搜索參數(shù)為insite�����,那么組裝成這樣一個網(wǎng)址:
http://www.sogou.com/sgo?query=SEOinsite=meeaxu.com
這個網(wǎng)址時可被收錄的、這個頁面的所有搜索結果均是指定網(wǎng)站的�����,將類似的網(wǎng)址在互聯(lián)網(wǎng)上進行傳播���,蜘蛛爬行到之后最終會入庫建立索引��,最后達到了我們的目的:讓搜索引擎給自己的網(wǎng)站鏈接����。
寫在最后
這種方法的時效性不高����,很多人都使用之后就會被修復。之所以要將原理清楚地描述出來�����,是為了描述黑帽方法的發(fā)現(xiàn)過程����。黑帽并不是簡單地做什么站群、群發(fā)外鏈什么的���,更多的是利用搜索引擎本身的漏洞來進行優(yōu)化���。本文僅僅是示例了一個非常簡單的黑帽方法發(fā)現(xiàn)過程��,更多大神都非常低調���,其發(fā)現(xiàn)的方法也并未在互聯(lián)網(wǎng)上傳播。本文僅僅是為了讓大家更了解黑帽��,并非鼓勵大家使用黑帽的方式來進行網(wǎng)站優(yōu)化���,不僅傷害用戶也為互聯(lián)網(wǎng)帶來了更多污染。我希望大家更多地去考慮用戶體驗���,去配合搜索引擎�,同樣能夠達到最終目的��。
