目錄
- 一�����、方案1(UDF)
- 演示案例
- 二���、方案2(解析binlog)
- 三����、附加
本文介紹MySQL與Redis緩存的同步的兩種方案
- 方案1:通過MySQL自動同步刷新Redis���,MySQL觸發(fā)器+UDF函數(shù)實現(xiàn)
- 方案2:解析MySQL的binlog實現(xiàn)��,將數(shù)據(jù)庫中的數(shù)據(jù)同步到Redis
一�����、方案1(UDF)
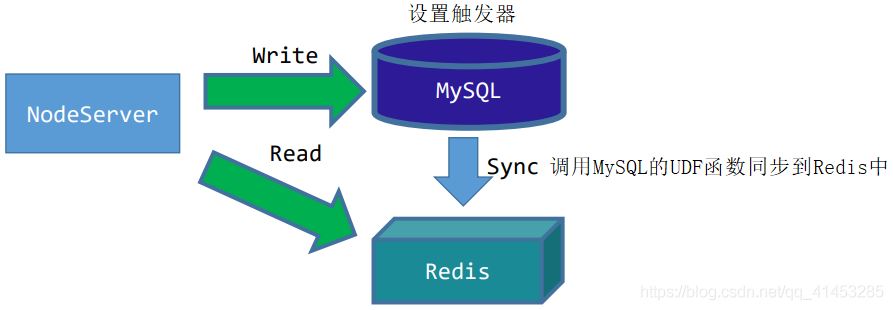
場景分析:當(dāng)我們對MySQL數(shù)據(jù)庫進行數(shù)據(jù)操作時����,同時將相應(yīng)的數(shù)據(jù)同步到Redis中���,同步到Redis之后��,查詢的操作就從Redis中查找
過程大致如下:
在MySQL中對要操作的數(shù)據(jù)設(shè)置觸發(fā)器Trigger����,監(jiān)聽操作
客戶端(NodeServer)向MySQL中寫入數(shù)據(jù)時,觸發(fā)器會被觸發(fā)�����,觸發(fā)之后調(diào)用MySQL的UDF函數(shù)
UDF函數(shù)可以把數(shù)據(jù)寫入到Redis中�,從而達到同步的效果
方案分析:
- 這種方案適合于讀多寫少,并且不存并發(fā)寫的場景
- 因為MySQL觸發(fā)器本身就會造成效率的降低����,如果一個表經(jīng)常被操作,這種方案顯示是不合適的
演示案例
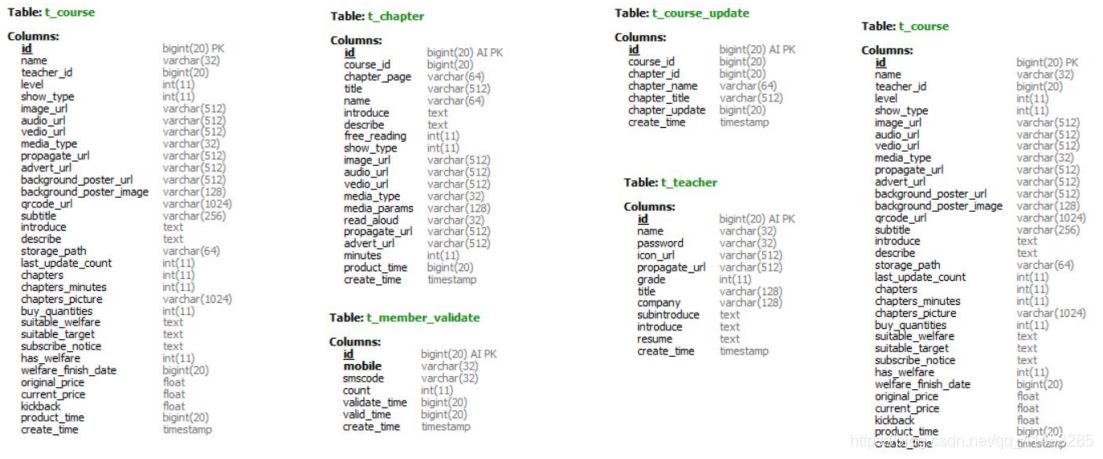
下面是MySQL的表
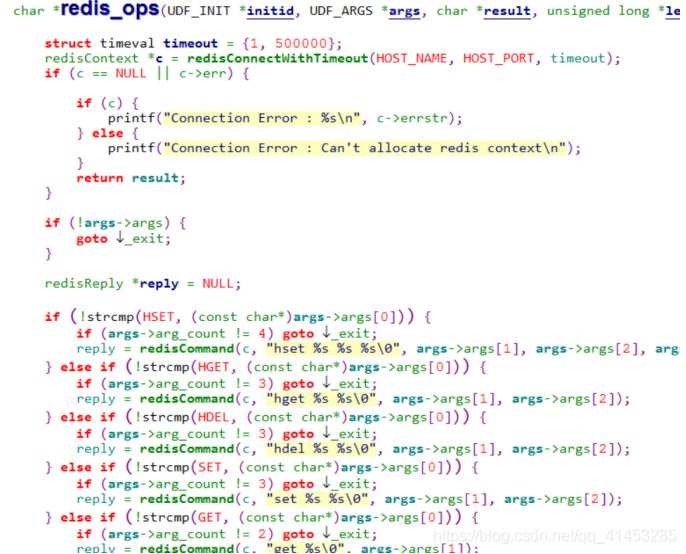
下面是UDF的解析代碼
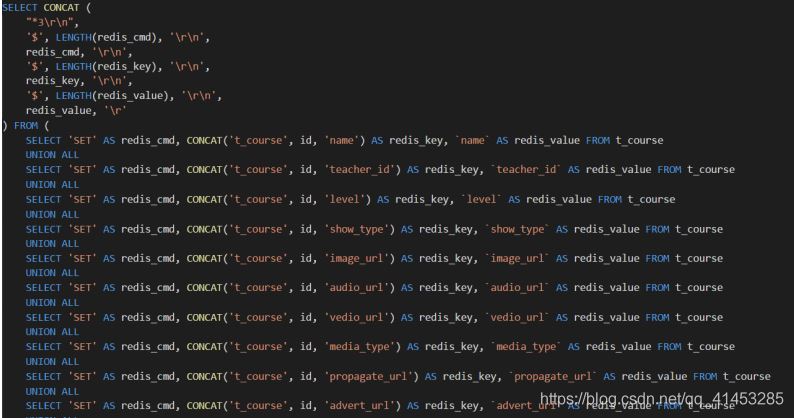
定義對應(yīng)的觸發(fā)器


二�、方案2(解析binlog)
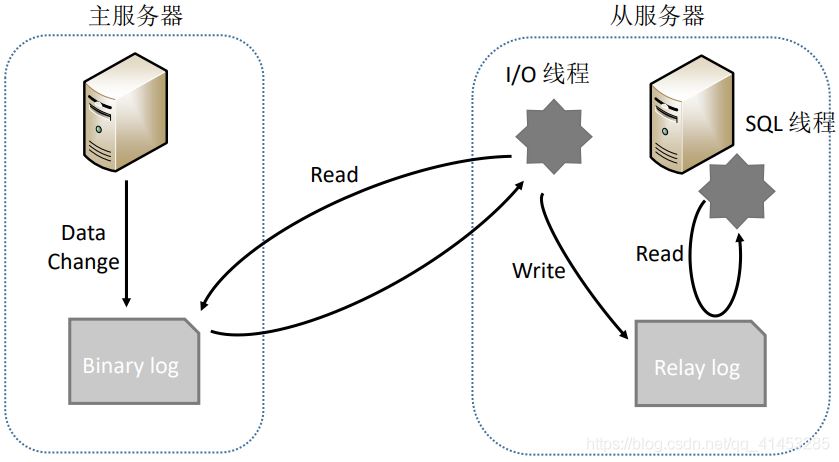
在介紹方案2之前我們先來介紹一下MySQL復(fù)制的原理,如下圖所示:
- 主服務(wù)器操作數(shù)據(jù)����,并將數(shù)據(jù)寫入Bin log
- 從服務(wù)器調(diào)用I/O線程讀取主服務(wù)器的Bin log,并且寫入到自己的Relay log中�����,再調(diào)用SQL線程從Relay log中解析數(shù)據(jù),從而同步到自己的數(shù)據(jù)庫中
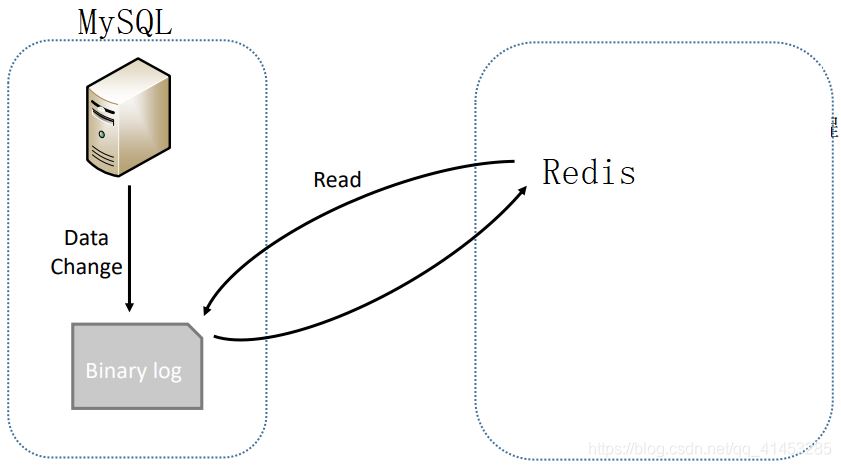
方案2就是:
- 上面MySQL的整個復(fù)制流程可以總結(jié)為一句話���,那就是:從服務(wù)器讀取主服務(wù)器Bin log中的數(shù)據(jù)���,從而同步到自己的數(shù)據(jù)庫中
- 我們方案2也是如此��,就是在概念上把主服務(wù)器改為MySQL���,把從服務(wù)器改為Redis而已(如下圖所示)���,當(dāng)MySQL中有數(shù)據(jù)寫入時,我們就解析MySQL的Bin log�����,然后將解析出來的數(shù)據(jù)寫入到Redis中���,從而達到同步的效果
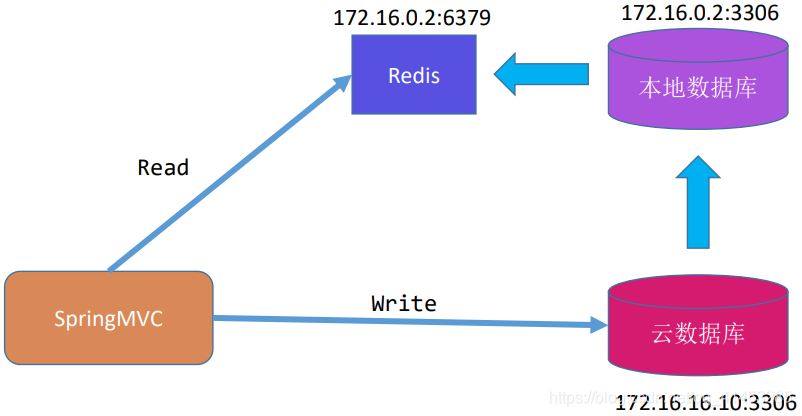
例如下面是一個云數(shù)據(jù)庫實例分析:
云數(shù)據(jù)庫與本地數(shù)據(jù)庫是主從關(guān)系���。云數(shù)據(jù)庫作為主數(shù)據(jù)庫主要提供寫,本地數(shù)據(jù)庫作為從數(shù)據(jù)庫從主數(shù)據(jù)庫中讀取數(shù)據(jù)
本地數(shù)據(jù)庫讀取到數(shù)據(jù)之后�,解析Bin log���,然后將數(shù)據(jù)寫入寫入同步到Redis中,然后客戶端從Redis讀數(shù)據(jù)
這個技術(shù)方案的難點就在于:如何解析MySQL的Bin Log�。但是這需要對binlog文件以及MySQL有非常深入的理解,同時由于binlog存在Statement/Row/Mixedlevel多種形式�����,分析binlog實現(xiàn)同步的工作量是非常大的
Canal開源技術(shù)
canal是阿里巴巴旗下的一款開源項目�����,純Java開發(fā)���?;跀?shù)據(jù)庫增量日志解析��,提供增量數(shù)據(jù)訂閱消費�����,目前主要支持了MySQL(也支持mariaDB)
開源參考地址有:https://github.com/liukelin/canal_mysql_nosql_sync
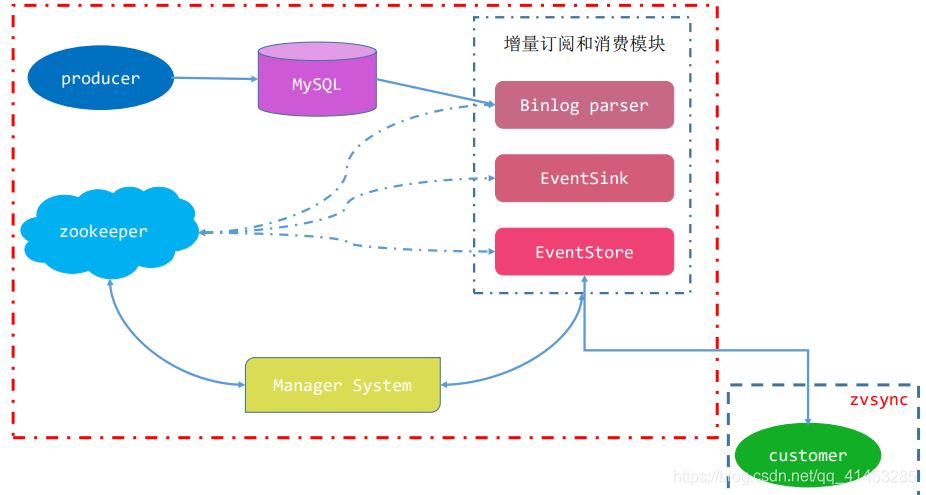
工作原理(模仿MySQL復(fù)制):
- canal模擬mysql slave的交互協(xié)議���,偽裝自己為mysql slave�,向mysql master發(fā)送dump協(xié)議
- mysql master收到dump請求,開始推送binary log給slave(也就是canal)
- canal解析binary log對象(原始為byte流)

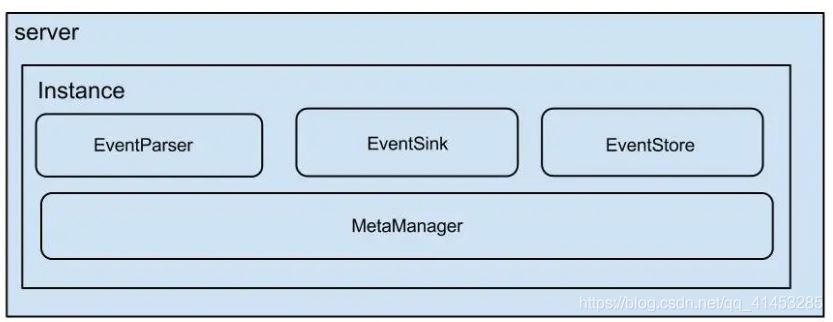
架構(gòu):
server代表一個canal運行實例��,對應(yīng)于一個jvm
instance對應(yīng)于一個數(shù)據(jù)隊列 (1個server對應(yīng)1..n個instance)
instance模塊:
- eventParser (數(shù)據(jù)源接入��,模擬slave協(xié)議和master進行交互���,協(xié)議解析)
- eventSink (Parser和Store鏈接器�,進行數(shù)據(jù)過濾�����,加工�,分發(fā)的工作)
- eventStore (數(shù)據(jù)存儲)
- metaManager (增量訂閱消費信息管理器)
大致的解析過程如下:
- parse解析MySQL的Bin log����,然后將數(shù)據(jù)放入到sink中
- sink對數(shù)據(jù)進行過濾,加工����,分發(fā)
- store從sink中讀取解析好的數(shù)據(jù)存儲起來
- 然后自己用設(shè)計代碼將store中的數(shù)據(jù)同步寫入Redis中就可以了
- 其中parse/sink是框架封裝好的,我們做的是store的數(shù)據(jù)讀取那一步
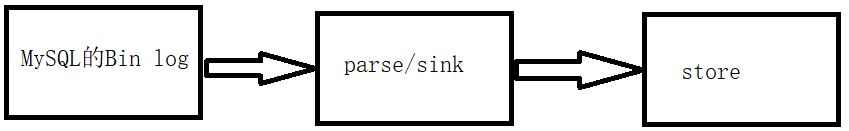
更多關(guān)于Cancl可以百度搜索
下面是運行拓撲圖
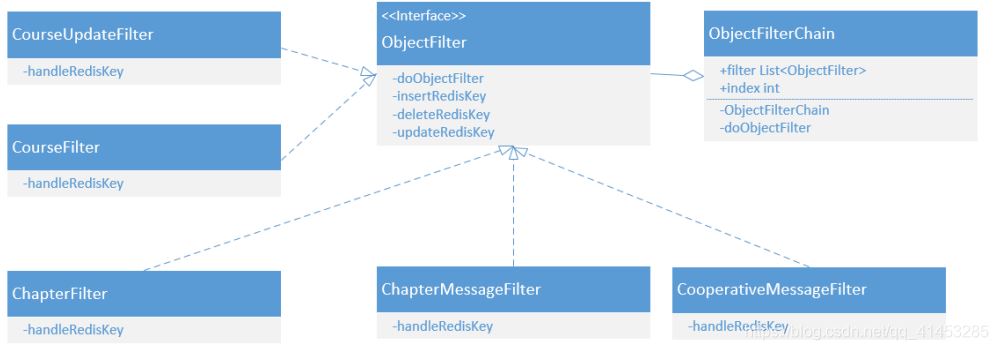
MySQL表的同步�����,采用責(zé)任鏈模式,每張表對應(yīng)一個Filter��。例如zvsync中要用到的類設(shè)計如下:
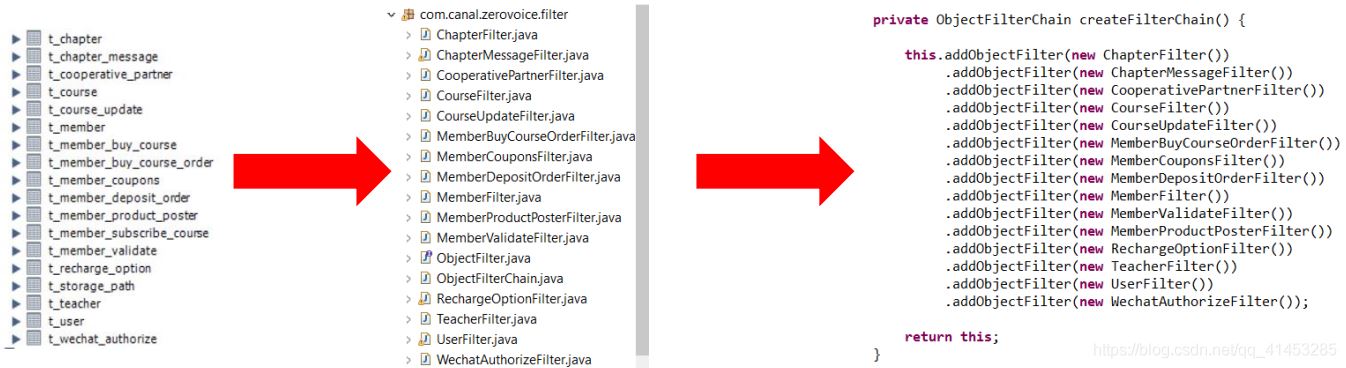
下面是具體化的zvsync中要用到的類�����,每當(dāng)新增或者刪除表時�,直接進行增刪就可以了
三、附加
本文上面所介紹的都是從MySQL中同步到緩存中���。但是在實際開發(fā)中可能有人會用下面的方案:
- 客戶端有數(shù)據(jù)來了之后�����,先將其保存到Redis中�,然后再同步到MySQL中
- 這種方案本身也是不安全/不可靠的����,因此如果Redis存在短暫的宕機或失效,那么會丟失數(shù)據(jù)

到此這篇關(guān)于淺談MySQL與redis緩存的同步方案的文章就介紹到這了,更多相關(guān)MySQL與redis緩存同步內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家�!
您可能感興趣的文章:- Java手動實現(xiàn)Redis的LRU緩存機制
- 淺談redis緩存在項目中的使用
- 詳解redis緩存與數(shù)據(jù)庫一致性問題解決
- 手動實現(xiàn)Redis的LRU緩存機制示例詳解
- 使用 Redis 緩存實現(xiàn)點贊和取消點贊的示例代碼
- 詳解Redis 緩存刪除機制(源碼解析)
- Redis 緩存實現(xiàn)存儲和讀取歷史搜索關(guān)鍵字的操作方法
- SpringCache 分布式緩存的實現(xiàn)方法(規(guī)避redis解鎖的問題)
- 詳解緩存穿透擊穿雪崩解決方案
