項目場景:
在使用selenium模塊進行數據爬取時����,通常會遇到爬取iframe中的內容。會因為定位的作用域問題爬取不到數據����。
問題描述:
我們以菜鳥教程的運行實例為案例。
按照正常的定位
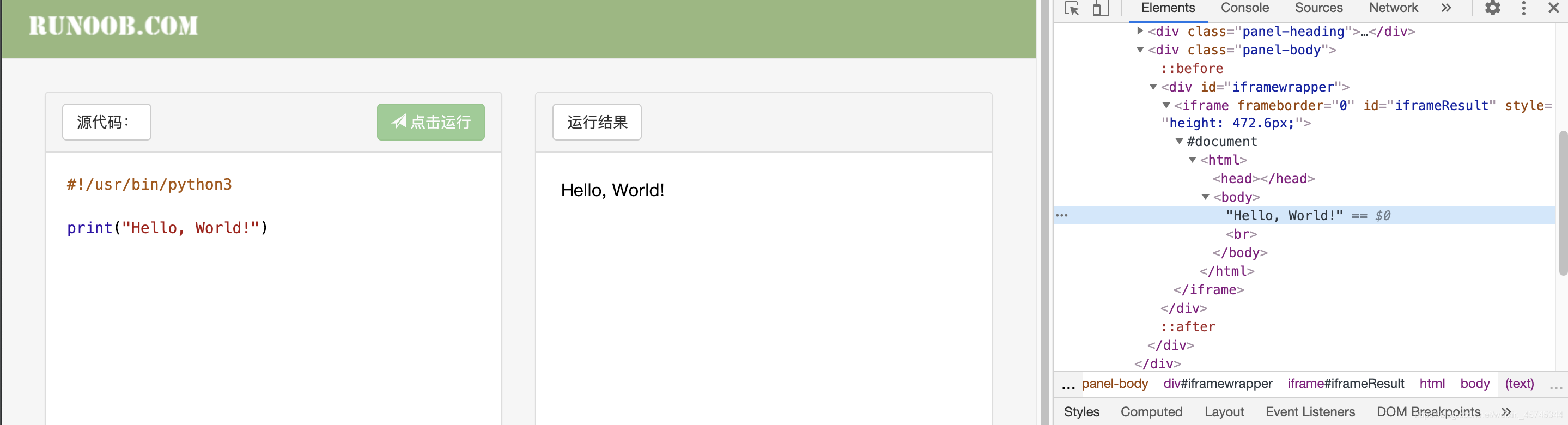
會以文本塊生成xpath為/html/body/text()��。這樣的話根據xpath進行如下代碼編寫�。
#!/user/bin/
# -*- coding:UTF-8 -*-
# Author:Master
from selenium import webdriver
import time
driver = webdriver.Chrome(executable_path="./chromedriver")
driver.get('https://www.runoob.com/try/runcode.php?filename=HelloWorldtype=python3')
time.sleep(2)
text = driver.find_element_by_xpath('/html/body').text
print(text)
time.sleep(5)
driver.quit()
執(zhí)行結果:

很明顯這并不是想要的結果。
原因分析:
當我們打開抓包工具定位到Hello, World!文本的時候會發(fā)現(xiàn)�,該文本是在一個iframe中。這樣的話我們xpath所定位到的內容則是大的html中的路徑���。我們需要的內容則是在iframe中的小的html中���。
解決方案:
通過分析發(fā)現(xiàn),想要解決問題的實質就是改變作用域����。通過switch_to.frame(‘id')方法來改變作用域就可以了。
重新編寫代碼:
#!/user/bin/
# -*- coding:UTF-8 -*-
# Author:Master
from selenium import webdriver
import time
driver = webdriver.Chrome(executable_path="./chromedriver")
driver.get('https://www.runoob.com/try/runcode.php?filename=HelloWorldtype=python3')
time.sleep(2)
driver.switch_to.frame('iframeResult')
text = driver.find_element_by_xpath('/html/body').text
print(text)
time.sleep(5)
driver.quit()
查看運行結果:

到此這篇關于Python爬蟲實現(xiàn)selenium處理iframe作用域問題的文章就介紹到這了,更多相關selenium iframe作用域內容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關文章希望大家以后多多支持腳本之家��!
您可能感興趣的文章:- selenium學習教程之定位以及切換frame(iframe)
- Python爬蟲之Selenium中frame/iframe表單嵌套頁面
- Selenium向iframe富文本框輸入內容過程圖解
- java selenium處理Iframe中的元素示例
