import numpy as np
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import KFold # 主要用于K折交叉驗證
# 導入iris數(shù)據(jù)集
iris = datasets.load_iris()
X = iris.data
y = iris.target
print(X.shape,y.shape)
# 定義想要搜索的K值�����,這里定義8個不同的值
ks = [1,3,5,7,9,11,13,15]
# 進行5折交叉驗證��,KFold返回的是每一折中訓練數(shù)據(jù)和驗證數(shù)據(jù)的index
# 假設數(shù)據(jù)樣本為:[1,3,5,6,11,12,43,12,44,2],總共10個樣本
# 則返回的kf的格式為(前面的是訓練數(shù)據(jù)����,后面的驗證集):
# [0,1,3,5,6,7,8,9],[2,4]
# [0,1,2,4,6,7,8,9],[3,5]
# [1,2,3,4,5,6,7,8],[0,9]
# [0,1,2,3,4,5,7,9],[6,8]
# [0,2,3,4,5,6,8,9],[1,7]
kf = KFold(n_splits = 5, random_state=2001, shuffle=True)
# 保存當前最好的k值和對應的準確率
best_k = ks[0]
best_score = 0
# 循環(huán)每一個k值
for k in ks:
curr_score = 0
for train_index,valid_index in kf.split(X):
# 每一折的訓練以及計算準確率
clf = KNeighborsClassifier(n_neighbors=k)
clf.fit(X[train_index],y[train_index])
curr_score = curr_score + clf.score(X[valid_index],y[valid_index])
# 求一下5折的平均準確率
avg_score = curr_score/5
if avg_score > best_score:
best_k = k
best_score = avg_score
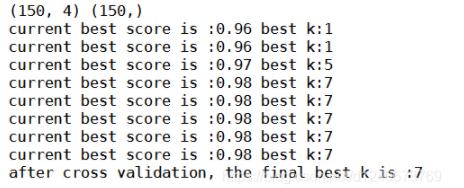
print("current best score is :%.2f" % best_score,"best k:%d" %best_k)
print("after cross validation, the final best k is :%d" %best_k)