目錄
- 前言
- 一��、首先導入相關的模塊
- 二�����、向網(wǎng)站發(fā)送請求并獲取網(wǎng)站數(shù)據(jù)
- 三����、拿到頁面數(shù)據(jù)之后對數(shù)據(jù)進行提取
- 四、獲取到小說詳情頁鏈接之后進行詳情頁二次訪問并獲取文章數(shù)據(jù)
- 五���、對小說詳情頁進行靜態(tài)頁面分析
- 六���、數(shù)據(jù)下載
前言
為了上班摸魚方便,今天自己寫了個爬取筆趣閣小說的程序��。好吧�,其實就是找個目的學習python,分享一下���。
一����、首先導入相關的模塊
import os
import requests
from bs4 import BeautifulSoup
二�、向網(wǎng)站發(fā)送請求并獲取網(wǎng)站數(shù)據(jù)

網(wǎng)站鏈接最后的一位數(shù)字為一本書的id值,一個數(shù)字對應一本小說�,我們以id為1的小說為示例。
進入到網(wǎng)站之后��,我們發(fā)現(xiàn)有一個章節(jié)列表��,那么我們首先完成對小說列表名稱的抓取
# 聲明請求頭
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36'
}
# 創(chuàng)建保存小說文本的文件夾
if not os.path.exists('./小說'):
os.mkdir('./小說/')
# 訪問網(wǎng)站并獲取頁面數(shù)據(jù)
response = requests.get('http://www.biquw.com/book/1/').text
print(response)
寫到這個地方同學們可能會發(fā)現(xiàn)了一個問題����,當我去正常訪問網(wǎng)站的時候為什么返回回來的數(shù)據(jù)是亂碼呢�����?
這是因為頁面html的編碼格式與我們python訪問并拿到數(shù)據(jù)的解碼格式不一致導致的,python默認的解碼方式為utf-8����,但是頁面編碼可能是GBK或者是GB2312等,所以我們需要讓python代碼很具頁面的解碼方式自動變化
#### 重新編寫訪問代碼
```python
response = requests.get('http://www.biquw.com/book/1/')
response.encoding = response.apparent_encoding
print(response.text)
'''
這種方式返回的中文數(shù)據(jù)才是正確的
'''
三���、拿到頁面數(shù)據(jù)之后對數(shù)據(jù)進行提取
當大家通過正確的解碼方式拿到頁面數(shù)據(jù)之后�,接下來需要完成靜態(tài)頁面分析了�。我們需要從整個網(wǎng)頁數(shù)據(jù)中拿到我們想要的數(shù)據(jù)(章節(jié)列表數(shù)據(jù))
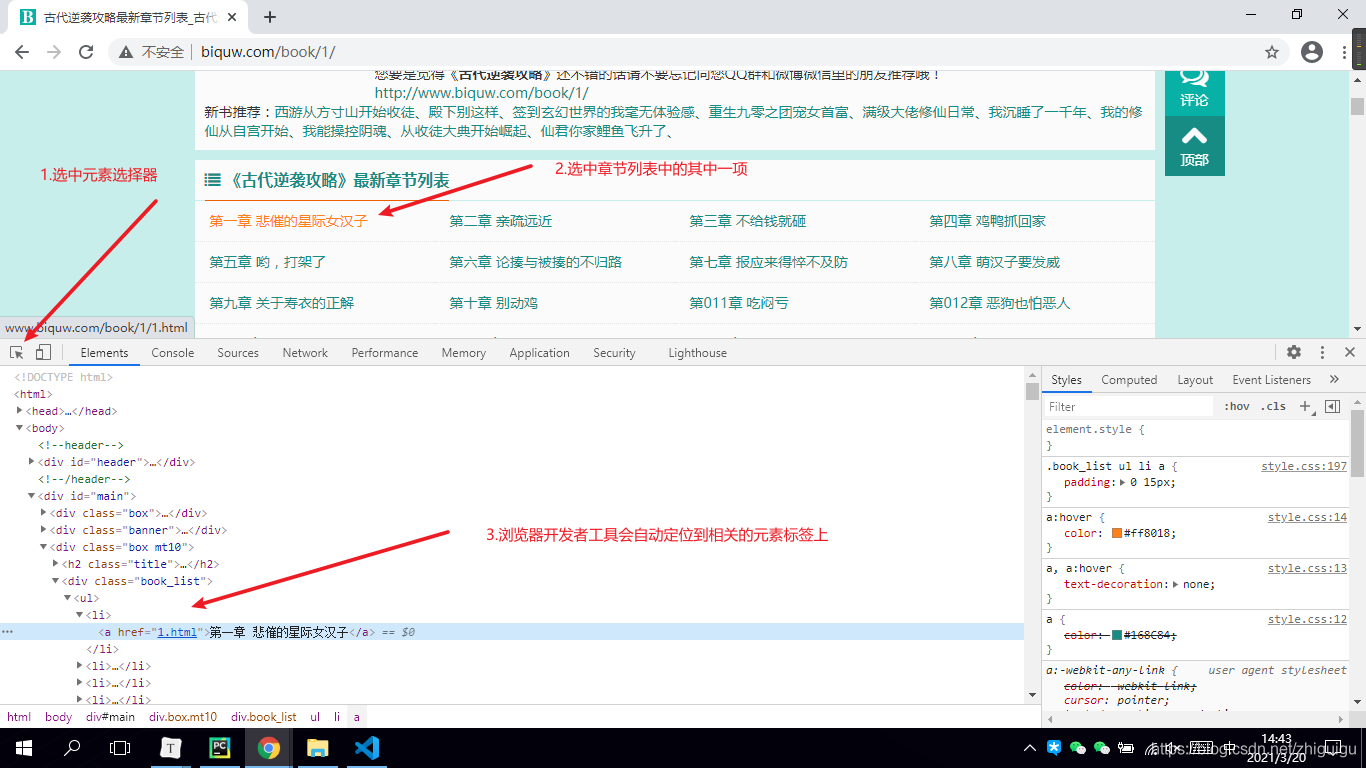
1.首先打開瀏覽器
2.按F12調(diào)出開發(fā)者工具
3.選中元素選擇器
4.在頁面中選中我們想要的數(shù)據(jù)并定位元素
5.觀察數(shù)據(jù)所存在的元素標簽
'''
根據(jù)上圖所示,數(shù)據(jù)是保存在a標簽當中的���。a的父標簽為li�����,li的父標簽為ul標簽����,ul標簽之上為div標簽。所以如果想要獲取整個頁面的小說章節(jié)數(shù)據(jù)����,那么需要先獲取div標簽。并且div標簽中包含了class屬性�����,我們可以通過class屬性獲取指定的div標簽�,詳情看代碼~
'''
# lxml: html解析庫 將html代碼轉(zhuǎn)成python對象,python可以對html代碼進行控制
soup = BeautifulSoup(response.text, 'lxml')
book_list = soup.find('div', class_='book_list').find_all('a')
# soup對象獲取批量數(shù)據(jù)后返回的是一個列表��,我們可以對列表進行迭代提取
for book in book_list:
book_name = book.text
# 獲取到列表數(shù)據(jù)之后��,需要獲取文章詳情頁的鏈接����,鏈接在a標簽的href屬性中
book_url = book['href']
四、獲取到小說詳情頁鏈接之后進行詳情頁二次訪問并獲取文章數(shù)據(jù)
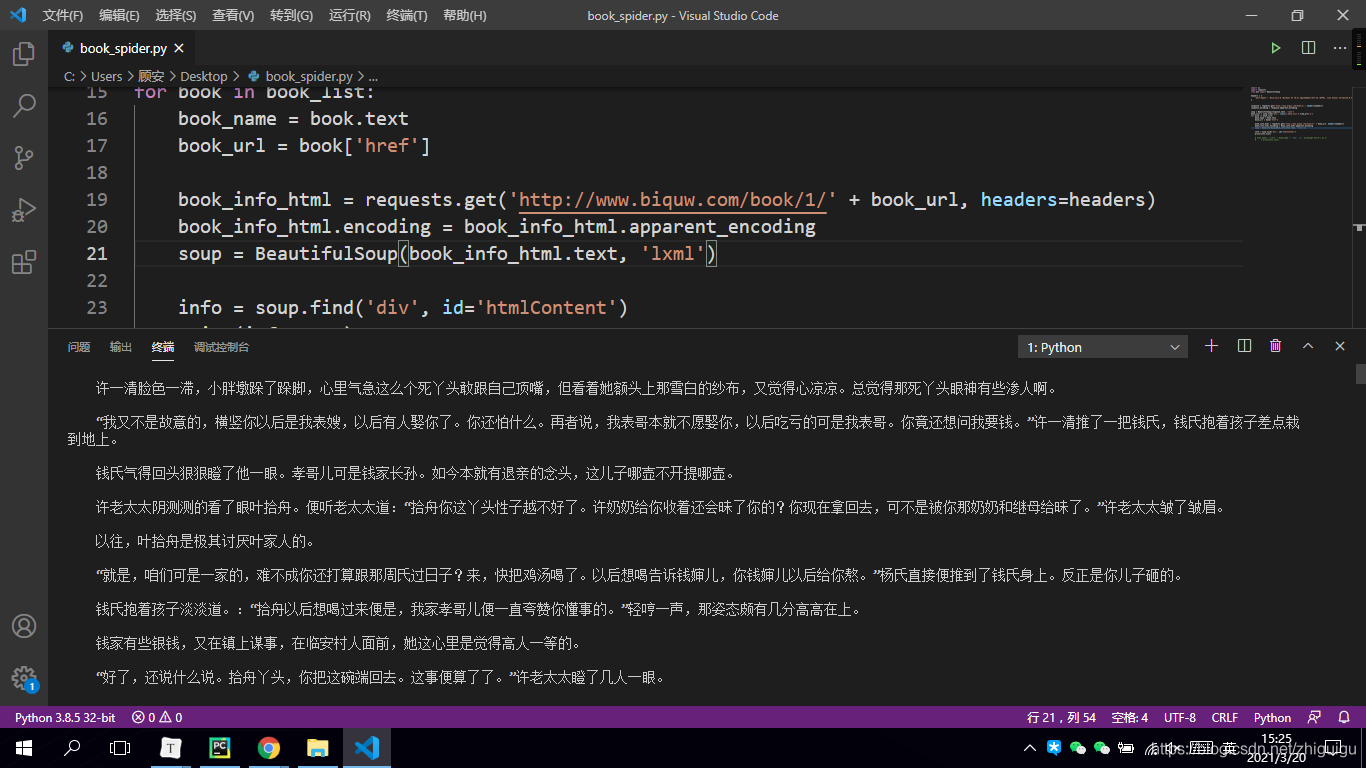
book_info_html = requests.get('http://www.biquw.com/book/1/' + book_url, headers=headers)
book_info_html.encoding = book_info_html.apparent_encoding
soup = BeautifulSoup(book_info_html.text, 'lxml')
五���、對小說詳情頁進行靜態(tài)頁面分析
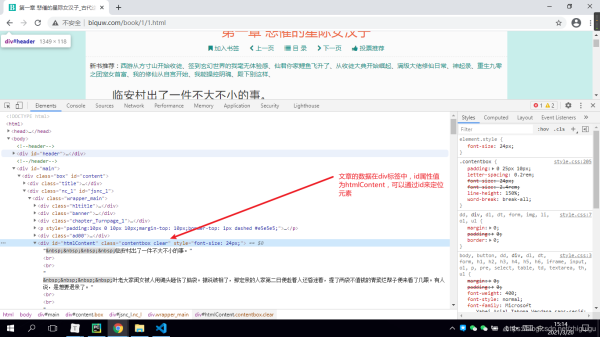
info = soup.find('div', id='htmlContent')
print(info.text)
六�����、數(shù)據(jù)下載
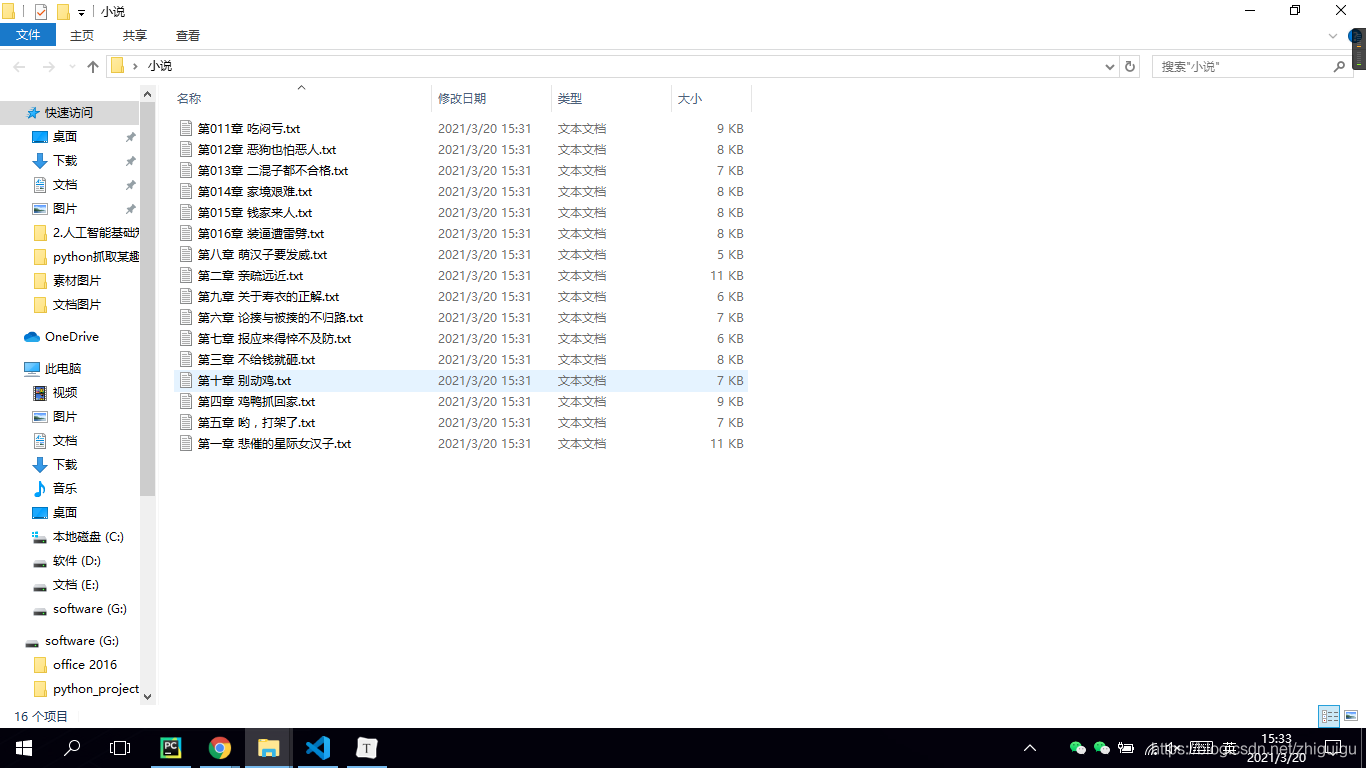
with open('./小說/' + book_name + '.txt', 'a', encoding='utf-8') as f:
f.write(info.text)
最后讓我們看一下代碼效果吧~
抓取的數(shù)據(jù)
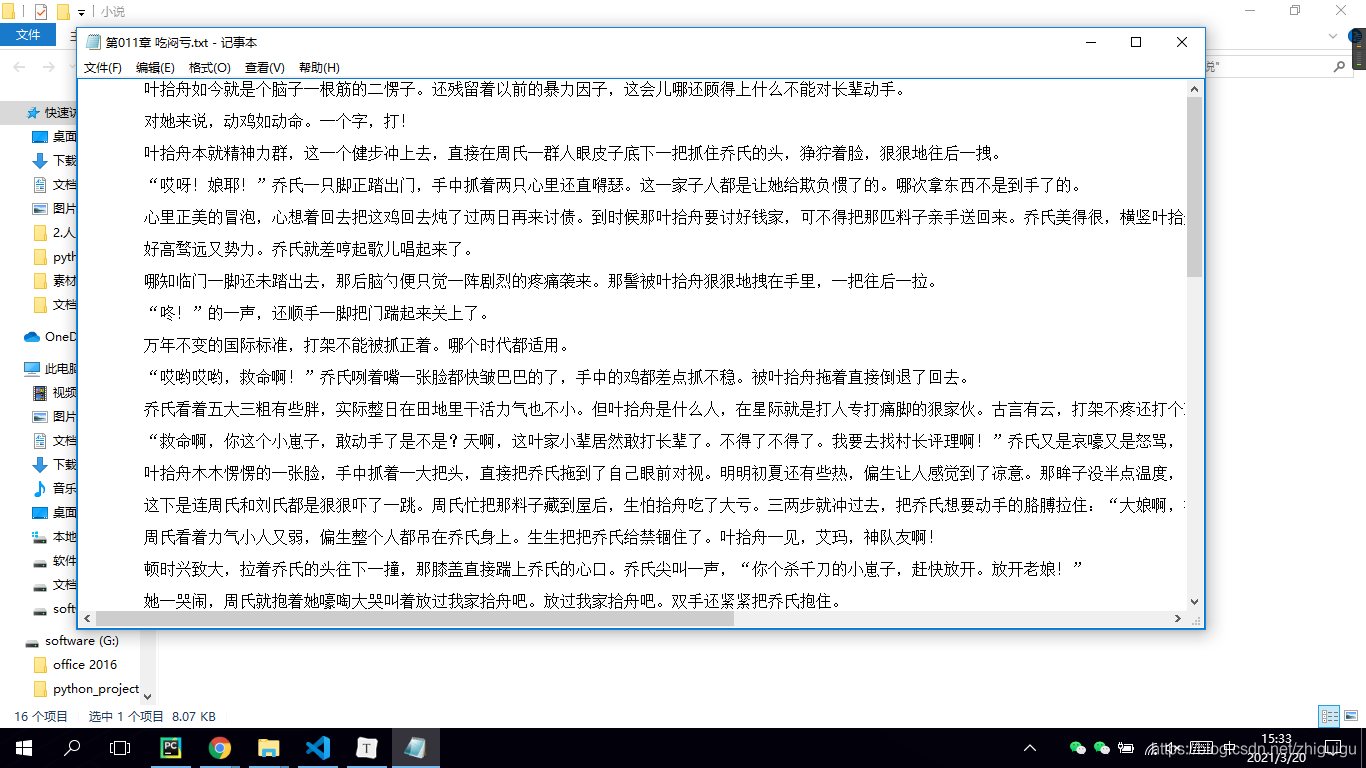
到此這篇關于python爬蟲之爬取筆趣閣小說的文章就介紹到這了,更多相關python爬取小說內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關文章希望大家以后多多支持腳本之家��!
您可能感興趣的文章:- python 爬取國內(nèi)小說網(wǎng)站
- Python爬蟲入門教程02之筆趣閣小說爬取
- python 爬取小說并下載的示例
- python爬取”頂點小說網(wǎng)“《純陽劍尊》的示例代碼
- Python爬取365好書中小說代碼實例
- Python實現(xiàn)的爬取小說爬蟲功能示例
- Python scrapy爬取起點中文網(wǎng)小說榜單
