目錄
- 實驗環(huán)境準備
- API 尋找 提取
- 代碼實現(xiàn)
- 項目鏈接
我身邊的很多小伙伴們在朋友圈里面曬著出去游玩的照片��,簡直了����,人多的不要不要的�����,長城被堵到水泄不通�����,老實人想想啊���,既然人這么多,哪都不去也是件好事��,沒事還可以刷刷 B 站 23333 ���。這時候老實人也有了一個大膽地想法���,能不能讓這些在旅游景點排隊的小伙伴們更快地打發(fā)時間呢?考慮到視頻的娛樂性和大眾觀看量��,我決定對 B 站新推出的小視頻功能下手���,于是我跑到B站去找API接口����,果不起然,B站在小視頻功能處提供了 API 接口���,小伙伴們有福了喲��!

B 站小視頻網(wǎng)址在這里哦:
http://vc.bilibili.com/p/eden/rank#/?tab=全部
此次實驗�����,我們爬取的是每日的小視頻排行榜前 top100
我們該如何去爬取呢��?�?��?
實驗環(huán)境準備
- Chrome 瀏覽器 (能使用開發(fā)者模式的瀏覽器都行)
- Vim (編輯器任選�����,老實人比較喜歡Vim界面�,所以才用這個啦)
- Python3 開發(fā)環(huán)境
- Kali Linux (其實隨便一個操作系統(tǒng)都行啦)
API 尋找 提取
我們通過 F12 打開開發(fā)者模式,然后在 Networking -> Name 字段下找到這個鏈接:

我們可以看到Request URL這個屬性值�����,我們向下滑動加載視頻的過程中��,發(fā)現(xiàn)只有這段url是不變的�����。
http://api.vc.bilibili.com/board/v1/ranking/top?
next_offset 會一直變化���,我們可以猜測���,這個可能就是獲取下一個視頻序號,我們只需要把這部分參數(shù)取出來�����,把 next_offset 寫成變量值����,用 JSON 的格式返回到目標網(wǎng)頁即可。

代碼實現(xiàn)
我們通過上面的嘗試寫了段代碼�,發(fā)現(xiàn) B 站在一定程度上做了反爬蟲操作,所以我們需要先獲取 headers 信息�����,否則下載下來的視頻是空的,然后定義 params 參數(shù)存儲 JSON 數(shù)據(jù)���,然后通過 requests.get 去獲取其參數(shù)值信息�,用 JSON 的格式返回到目標網(wǎng)頁即可�,實現(xiàn)代碼如下:
def get_json(url):
headers = {
'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
params = {
'page_size': 10,
'next_offset': str(num),
'tag': '今日熱門',
'platform': 'pc'
}
try:
html = requests.get(url,params=params,headers=headers)
return html.json()
except BaseException:
print('request error')
pass
為了能夠清楚的看到我們下載的情況,我們折騰了一個下載器上去�����,實現(xiàn)代碼如下:
def download(url,path):
start = time.time() # 開始時間
size = 0
headers = {
'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
response = requests.get(url,headers=headers,stream=True) # stream屬性必須帶上
chunk_size = 1024 # 每次下載的數(shù)據(jù)大小
content_size = int(response.headers['content-length']) # 總大小
if response.status_code == 200:
print('[文件大小]:%0.2f MB' %(content_size / chunk_size / 1024)) # 換算單位
with open(path,'wb') as file:
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
size += len(data) # 已下載的文件大小
效果如下:

將上面的代碼進行匯總�,整個實現(xiàn)過程如下:
#!/usr/bin/env python
#-*-coding:utf-8-*-
import requests
import random
import time
def get_json(url):
headers = {
'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
params = {
'page_size': 10,
'next_offset': str(num),
'tag': '今日熱門',
'platform': 'pc'
}
try:
html = requests.get(url,params=params,headers=headers)
return html.json()
except BaseException:
print('request error')
pass
def download(url,path):
start = time.time() # 開始時間
size = 0
headers = {
'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
response = requests.get(url,headers=headers,stream=True) # stream屬性必須帶上
chunk_size = 1024 # 每次下載的數(shù)據(jù)大小
content_size = int(response.headers['content-length']) # 總大小
if response.status_code == 200:
print('[文件大小]:%0.2f MB' %(content_size / chunk_size / 1024)) # 換算單位
with open(path,'wb') as file:
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
size += len(data) # 已下載的文件大小
if __name__ == '__main__':
for i in range(10):
url = 'http://api.vc.bilibili.com/board/v1/ranking/top?'
num = i*10 + 1
html = get_json(url)
infos = html['data']['items']
for info in infos:
title = info['item']['description'] # 小視頻的標題
video_url = info['item']['video_playurl'] # 小視頻的下載鏈接
print(title)
# 為了防止有些視頻沒有提供下載鏈接的情況
try:
download(video_url,path='%s.mp4' %title)
print('成功下載一個!')
except BaseException:
print('涼涼,下載失敗')
pass
time.sleep(int(format(random.randint(2,8)))) # 設(shè)置隨機等待時間
爬取效果圖如下:
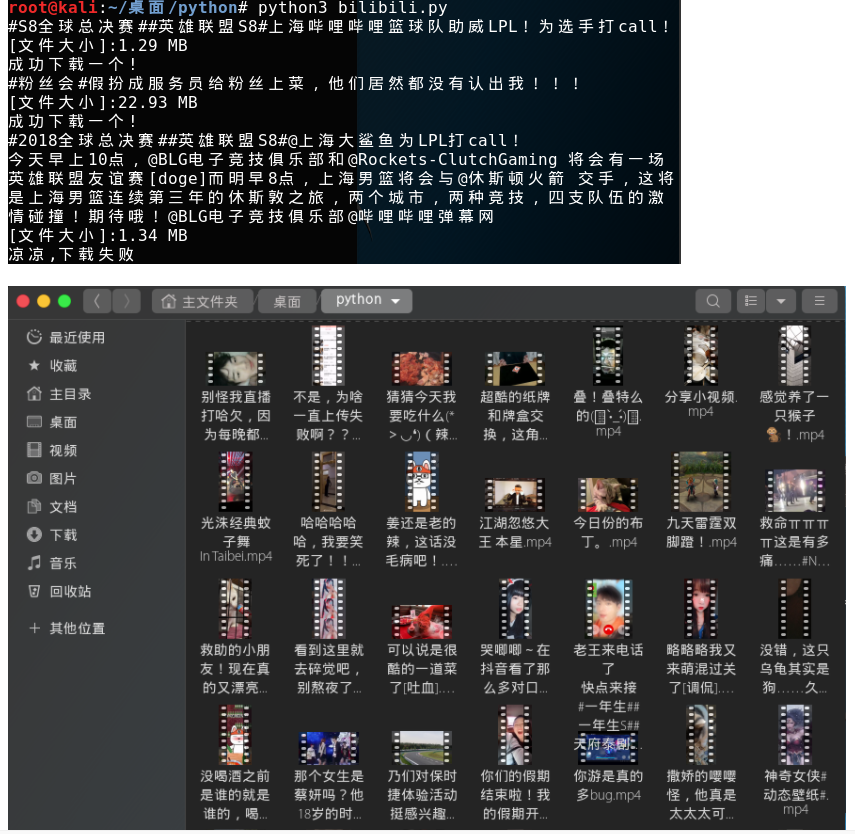
似乎爬取的效果還可以,當然喜歡的朋友不要忘記點贊分享轉(zhuǎn)發(fā)哦���。
項目鏈接
Github
以上就是寫一個 Python 腳本自動爬取 Bilibili 小視頻的詳細內(nèi)容����,更多關(guān)于Python 爬取 Bilibili 小視頻的資料請關(guān)注腳本之家其它相關(guān)文章���!
您可能感興趣的文章:- 用python制作個視頻下載器
- python3寫爬取B站視頻彈幕功能
- Python基于Tkinter開發(fā)一個爬取B站直播彈幕的工具
- Python編程實現(xiàn)下載器自動爬取采集B站彈幕示例
