看到代碼里面有這個

1 class ResNeXt101(nn.Module):
2 def __init__(self):
3 super(ResNeXt101, self).__init__()
4 net = resnext101()
# print(os.getcwd(), net)
5 net = list(net.children()) # net.children()得到resneXt 的表層網(wǎng)絡(luò)
# for i, value in enumerate(net):
# print(i, value)
6 self.layer0 = nn.Sequential(net[:3]) # 將前三層打包0���, 1, 2兩層
print(self.layer0)
7 self.layer1 = nn.Sequential(*net[3: 5]) # 將3, 4兩層打包
8 self.layer2 = net[5]
9 self.layer3 = net[6]
可以看到代碼中的第六行(序號自己去掉����,我打上去的) self.layer0 = nn.Sequential(net[:3])和
第七行self.layer1 = nn.Sequential(*net[3: 5])
有一個nn.Sequential(net[:3])
和nn.Sequential(*net[3: 5])
今天不講nn.Sequential()用法,意義�,作用因為我也不咋明白。驚天就說*net[3: 5]這個東西為啥要帶“ * ”
當代碼中不帶*的時候��,運行會出現(xiàn)以下問題
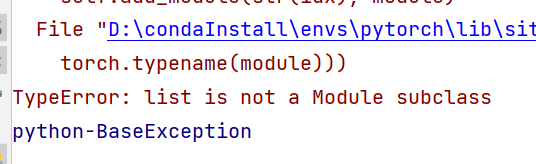
意思就是列表不是子類��,就是說參數(shù)不對
net = list(net.children())
這一行代碼是將模型的每一層取出來構(gòu)建一個列表��,自己試著打印就可以�。大概的輸出就是[conv()����,BatchNorm2d(), ReLU����,MaxPool2d]等等

總共是是個元素,和一般的列表不太一樣���。
當我們?nèi)?code>net[:3]的時候�,傳進去的參數(shù)是一個列表,但是我們用*net[:3]的時候傳進去的是單個元素
list1 = ["conv", ("relu", "maxing"), ("relu", "maxing", 3), 3]
list2 = [list1[:1]]
list3 = [*list1[:1]]
print("list2:{}, *list1[:2]:{}".format(list1[:1], *list1[:1]))

結(jié)果不帶✳的是列表�����,帶✳的是元素�����,所以nn.Sequential(*net[3: 5])中的*net[3: 5]就是給nn.Sequential()這個容器中傳入多個層���。
到此這篇關(guān)于pytorch中的nn.Sequential(*net[3: 5])是啥意思的文章就介紹到這了,更多相關(guān)pytorch nn.Sequential(*net[3: 5])內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家�����!
您可能感興趣的文章:- pytorch_detach 切斷網(wǎng)絡(luò)反傳方式
- pytorch 禁止/允許計算局部梯度的操作
- 如何利用Pytorch計算三角函數(shù)
- 聊聊PyTorch中eval和no_grad的關(guān)系
- Pytorch實現(xiàn)圖像識別之數(shù)字識別(附詳細注釋)
- Pytorch實現(xiàn)全連接層的操作
- pytorch 優(yōu)化器(optim)不同參數(shù)組,不同學(xué)習(xí)率設(shè)置的操作
- PyTorch 如何將CIFAR100數(shù)據(jù)按類標歸類保存
- PyTorch的Debug指南
- Python深度學(xué)習(xí)之使用Pytorch搭建ShuffleNetv2
- win10系統(tǒng)配置GPU版本Pytorch的詳細教程
- pytorch visdom安裝開啟及使用方法
- PyTorch CUDA環(huán)境配置及安裝的步驟(圖文教程)
- pytorch中的nn.ZeroPad2d()零填充函數(shù)實例詳解
- 使用pytorch實現(xiàn)線性回歸
- pytorch實現(xiàn)線性回歸以及多元回歸
- PyTorch學(xué)習(xí)之軟件準備與基本操作總結(jié)
