目錄
- 一、前言
- 二�����、問答平臺
- 三�����、原頁面效果
- 四���、抓包
- 五��、編寫代碼
- 六��、總結
一��、前言
今天教大家如何用Python爬蟲去搭建一個「生活常識解答」機器人����。
思路:這個機器人主要是依托于“阿里達摩院發(fā)布的語言模型PLUG”�����,通過爬蟲的方式�����,發(fā)送post請求(提問),然后返回json數(shù)據(jù)(回答)
二����、問答平臺
這個「生活常識解答」機器人采用的是:阿里達摩院發(fā)布的語言模型PLUG(最近剛發(fā)布的,目前是測試階段)

該模型參數(shù)規(guī)模達270億����,采用1TB以上高質量中文文本訓練數(shù)據(jù)��,包括了新聞����、小說、詩歌���、常識問答等類型����。
三��、原頁面效果
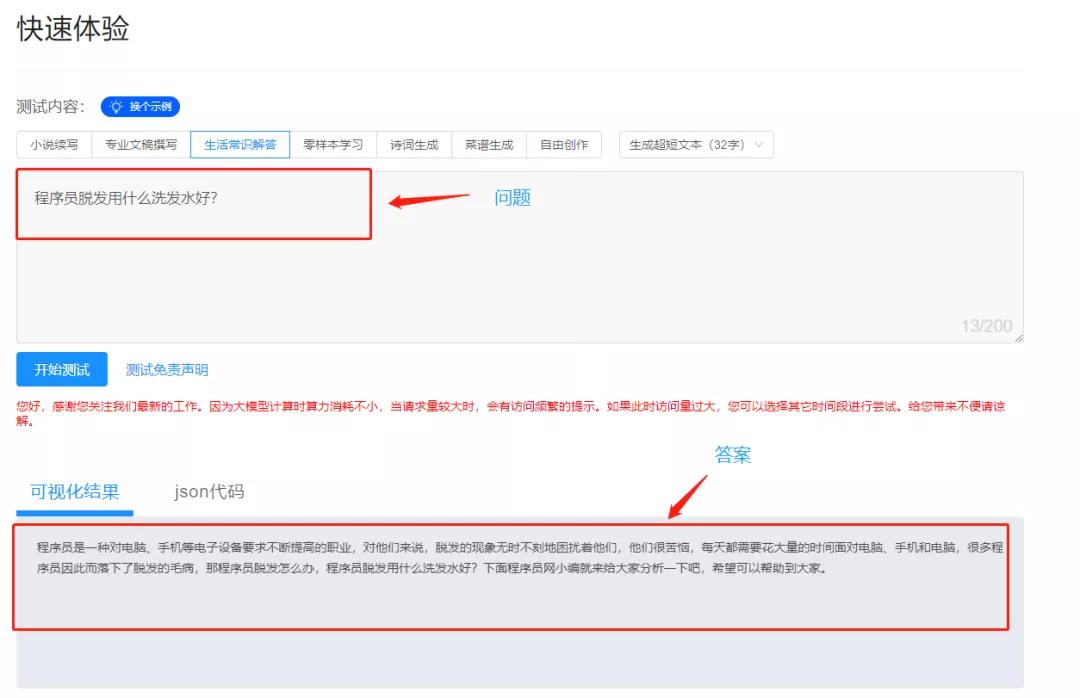
這里是需要登錄阿里云賬號���,登錄之后可以在網(wǎng)頁進行測試問答�����!
因此我們下面將通過抓包方式獲取這個問答的請求鏈接���,然后在python代碼中requests發(fā)送post請求去進行提問���,然后返回結果(答案)。
四��、抓包
在瀏覽器里面F12����,點擊network,然后點擊一下提問�����,獲取鏈接��。
首先是發(fā)送的參數(shù)(提問)
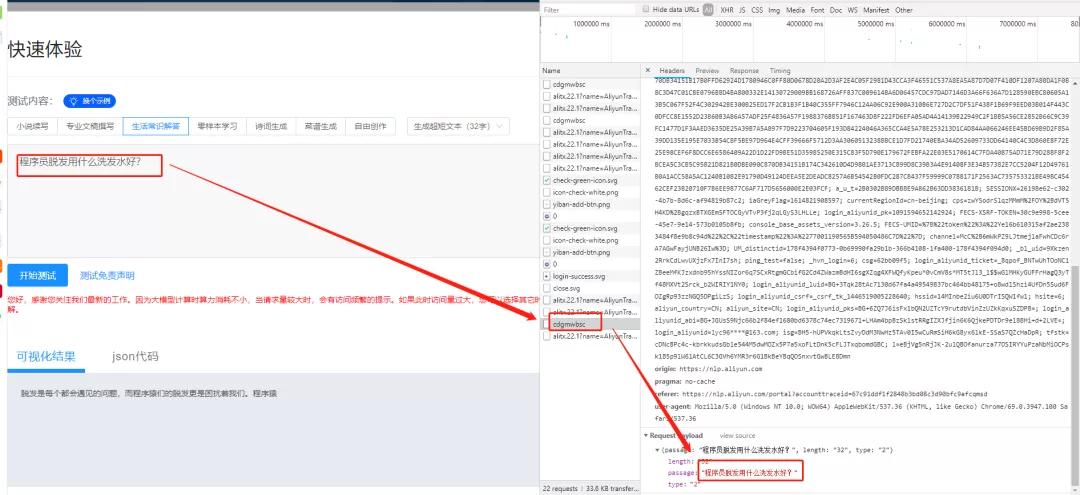
然后是返回的json數(shù)據(jù)
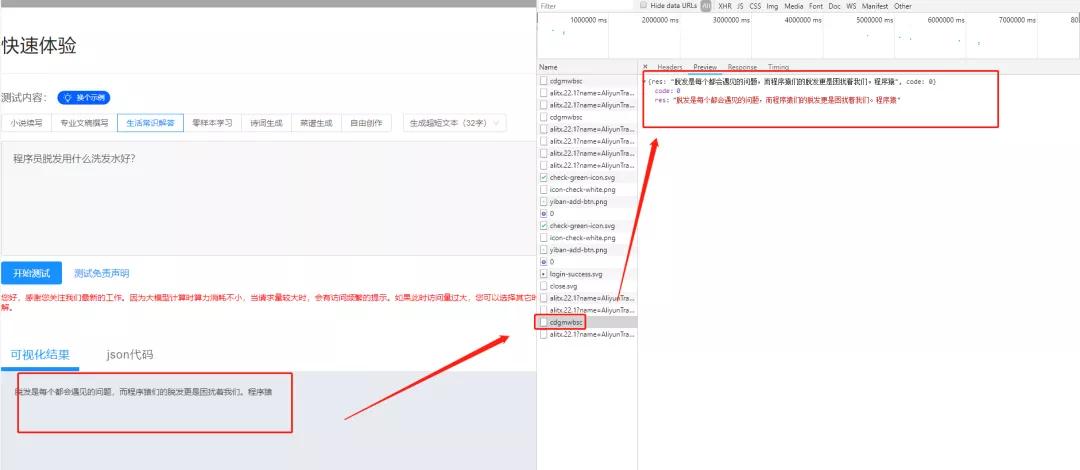
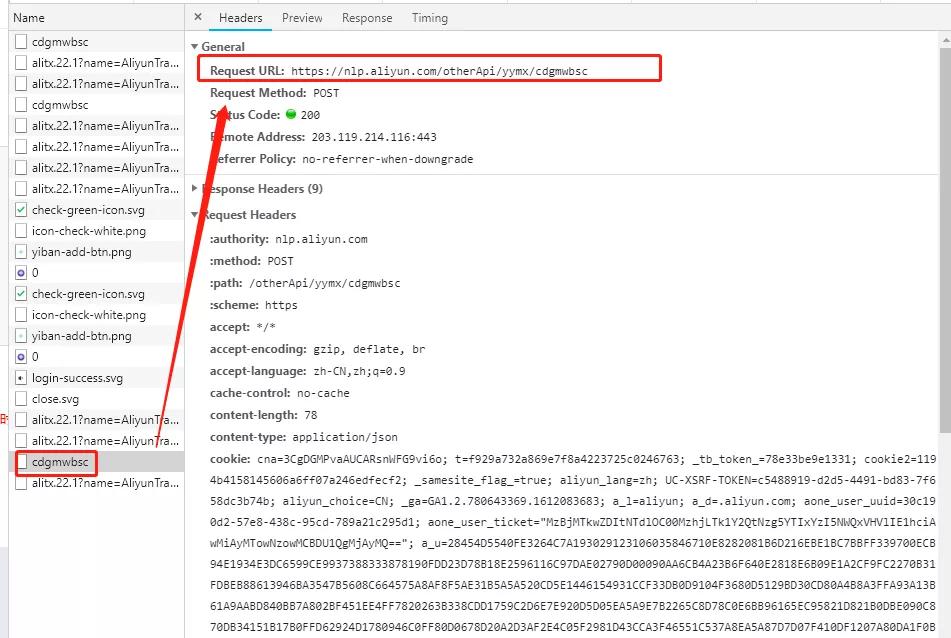
因此這個數(shù)據(jù)包的相關信息(請求鏈接�����,參數(shù),返回結果)我們已經(jīng)知道了���,下面開始編寫python代碼
五��、編寫代碼
首先是導入python庫和請求頭
import requests
import json
header={
'content-type':'application/json',
'cookie':'上面頁面中你自己的cookie',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36',
}
經(jīng)過測試��,有用的請求頭參數(shù)是上面三個(content-type�、cookie�����、User-Agent)�����,缺一不可�。
參數(shù)(其中q是問題���,length是返回答案長度���,type是對應常識問題)
q = "程序員脫發(fā)用什么洗發(fā)水好?"
data = {
'length':'128',
'type':'2',
'passage':q,
}
發(fā)送請求
url = "https://nlp.aliyun.com/otherApi/yymx/cdgmwbsc"
text = requests.post(url,data = json.dumps(data),headers=header).json()
print(text['res'])
返回結果

下面為了能夠多輪提問,將請求部分代碼放到循環(huán)中(如果輸入是exit則退出循環(huán))

六���、總結
今天小編主要就教大家用Python爬蟲去搭建一個「生活常識解答」機器人�����。
這個機器人主要是依托于“阿里達摩院發(fā)布的語言模型PLUG”���,通過爬蟲的方式,發(fā)送post請求(提問)���,然后返回json數(shù)據(jù)(回答)��。輕松實現(xiàn)多輪提問����。
到此這篇關于python爬蟲之生活常識解答機器人的文章就介紹到這了,更多相關python機器人內容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關文章希望大家以后多多支持腳本之家�����!
您可能感興趣的文章:- Python中利用aiohttp制作異步爬蟲及簡單應用
- Python爬蟲之線程池的使用
- python基礎之爬蟲入門
- python爬蟲請求庫httpx和parsel解析庫的使用測評
- Python爬蟲之爬取最新更新的小說網(wǎng)站
- 用Python爬蟲破解滑動驗證碼的案例解析
- Python爬蟲之必備chardet庫
- Python爬蟲框架-scrapy的使用
- Python爬蟲之爬取二手房信息
- python爬蟲之爬取百度翻譯
- python爬蟲基礎之簡易網(wǎng)頁搜集器
- Django利用Cookie實現(xiàn)反爬蟲的例子
- Python異步爬蟲實現(xiàn)原理與知識總結
