目錄
- 一����、通用爬蟲
- 二��、搜索引擎的局限性
- 三���、Robots協(xié)議
- 四��、請求與相應
一��、通用爬蟲
通用網(wǎng)絡(luò)爬蟲是搜索引擎抓取系統(tǒng)(Baidu��、Google���、Sogou等)的一個重要組成部分����。主要目的是將互聯(lián)網(wǎng)上的網(wǎng)頁下載到本地�,形成一個互聯(lián)網(wǎng)內(nèi)容的鏡像備份。為搜索引擎提供搜索支持�����。
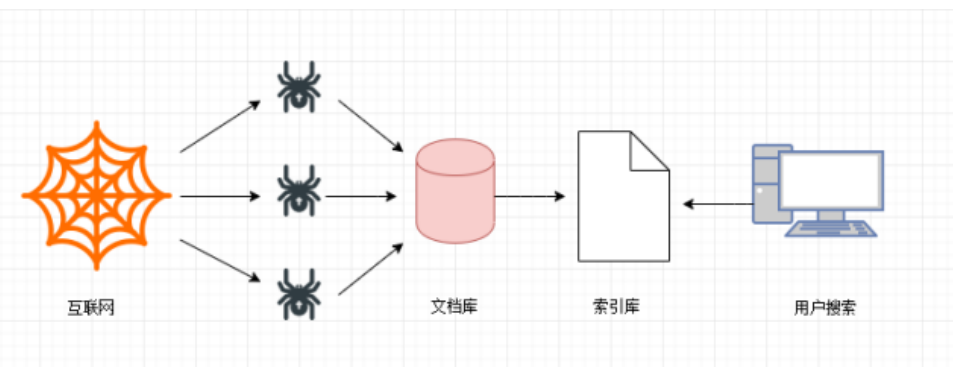
第一步
搜索引擎去成千上萬個網(wǎng)站抓取數(shù)據(jù)�����。
第二步
搜索引擎通過爬蟲爬取到的網(wǎng)頁�����,將數(shù)據(jù)存入原始頁面數(shù)據(jù)庫(也就是文檔庫)���。其中的頁面數(shù)據(jù)與用戶瀏覽器得到的HTML是完全—樣的��。
第三步
搜索引擎將爬蟲抓取回來的頁面���,進行各種步驟的預處理:中文分詞����,消除噪音���,索引處理���。。�。
搜索引擎在對信息進行組織和處理后,為用戶提供關(guān)鍵字檢索服務�,將用戶檢索相關(guān)的信息展示給用戶。展示的時候會進行排名�����。
二���、搜索引擎的局限性
- 搜索引擎抓取的是整個網(wǎng)頁,不是具體詳細的信息����。
- 搜索引擎無法提供針對具體某個客戶需求的搜索結(jié)果����。
聚焦爬蟲
針對通用爬蟲的這些情況�,聚焦爬蟲技術(shù)得以廣泛使用。聚焦爬蟲����,是"面向特定主題需求"的一種網(wǎng)絡(luò)爬蟲程序,它與通用搜索引擎爬蟲的區(qū)別在于:聚焦爬蟲在實施網(wǎng)頁抓取時會對內(nèi)容進行處理篩選�����,盡量保證只抓取與需求相關(guān)的網(wǎng)頁數(shù)據(jù)�����。
三�、Robots協(xié)議
robots是網(wǎng)站跟爬蟲間的協(xié)議,用簡單直接的txt格式文本方式告訴對應的爬蟲被允許的權(quán)限�,也就是說robots.txt是搜索引擎中訪問網(wǎng)站的時候要查看的第一個文件。當一個搜索蜘蛛訪問一個站點時��,它會首先檢查該站點根目錄下是否存在robots.txt�����,如果存在,搜索機器人就會按照該文件中的內(nèi)容來確定訪問的范圍;如果該文件不存在���,所有的搜索蜘蛛將能夠訪問網(wǎng)站上所有沒有被口令保護的頁面�����?���!俣劝倏?/p>
Robots協(xié)議也叫爬蟲協(xié)議���、機器人協(xié)議等,全稱是“網(wǎng)絡(luò)爬蟲排除標準”(Robots ExclusionProtocol)���,網(wǎng)站通過Robots協(xié)議告訴搜索引擎哪些頁面可以抓取�����,哪些頁面不能抓取���,例如:
淘寶: https://www.taobao.com/robots.txt
百度: https://www.baidu.com/robots.txt
四、請求與相應
網(wǎng)絡(luò)通信由兩部分組成:客戶端請求消息與服務器響應消息
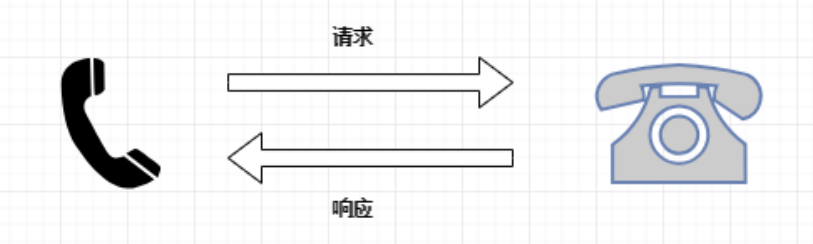
瀏覽器發(fā)送HTTP請求的過程:
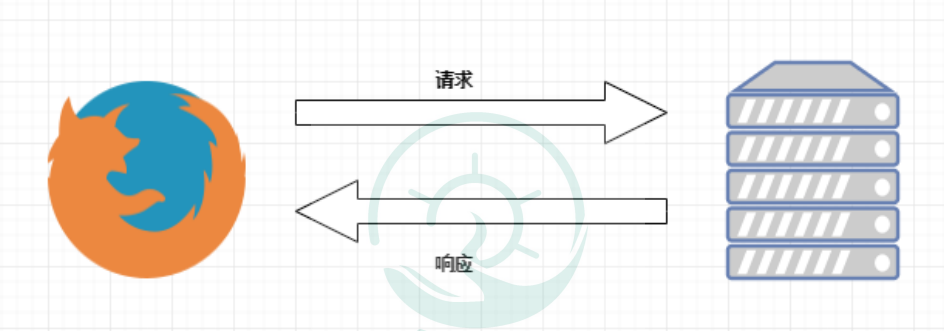
1.當我們在瀏覽器輸入URL https://www.baidu.com的時候����,瀏覽器發(fā)送一個Request請求去
獲取 https://www.baidu.com 的html文件,服務器把Response文件對象發(fā)送回給瀏覽器�。
2.瀏覽器分析Response中的HTML,發(fā)現(xiàn)其中引用了很多其他文件�,比如Images文件,CSS文件�,JS文件���。瀏覽器會自動再次發(fā)送Request去獲取圖片,CSS文件�,或者JS文件��。
3.當所有的文件都下載成功后���,網(wǎng)頁會根據(jù)HTML語法結(jié)構(gòu)�,完整的顯示出來了�����。
實際上我們通過學習爬蟲技術(shù)爬取數(shù)據(jù),也是向服務器請求數(shù)據(jù),獲取服務器響應數(shù)據(jù)的過程����。
到此這篇關(guān)于Python爬蟲基礎(chǔ)之爬蟲的分類知識總結(jié)的文章就介紹到這了,更多相關(guān)Python爬蟲的分類內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- Python爬蟲數(shù)據(jù)的分類及json數(shù)據(jù)使用小結(jié)
- python爬蟲scrapy圖書分類實例講解
- Python爬蟲實現(xiàn)的根據(jù)分類爬取豆瓣電影信息功能示例
- Python異步爬蟲實現(xiàn)原理與知識總結(jié)
- Python爬蟲之線程池的使用
- python基礎(chǔ)之爬蟲入門
- python爬蟲請求庫httpx和parsel解析庫的使用測評
- Python爬蟲之爬取最新更新的小說網(wǎng)站
- 用Python爬蟲破解滑動驗證碼的案例解析
