通常,由于類別不均衡����,需要使用weighted cross entropy loss平衡�。
def inverse_freq(label):
"""
輸入label [N,1,H,W],1是channel數(shù)目
"""
den = label.sum() # 0
_,_,h,w= label.shape
num = h*w
alpha = den/num # 0
return torch.tensor([alpha, 1-alpha]).cuda()
# train
...
loss1 = F.cross_entropy(out1, label.squeeze(1).long(), weight=inverse_freq(label))
補充:Pytorch踩坑記之交叉熵(nn.CrossEntropy�,nn.NLLLoss,nn.BCELoss的區(qū)別和使用)
在Pytorch中的交叉熵函數(shù)的血淚史要從nn.CrossEntropyLoss()這個損失函數(shù)開始講起���。
從表面意義上看����,這個函數(shù)好像是普通的交叉熵函數(shù)�,但是如果你看過一些Pytorch的資料,會告訴你這個函數(shù)其實是softmax()和交叉熵的結合體��。
然而如果去官方看這個函數(shù)的定義你會發(fā)現(xiàn)是這樣子的:

哇����,竟然是nn.LogSoftmax()和nn.NLLLoss()的結合體,這倆都是什么玩意兒啊��。再看看你會發(fā)現(xiàn)甚至還有一個損失叫nn.Softmax()以及一個叫nn.nn.BCELoss()��。
我們來探究下這幾個損失到底有何種關系�。
nn.Softmax和nn.LogSoftmax
首先nn.Softmax()官網(wǎng)的定義是這樣的:

嗯...就是我們認識的那個softmax。那nn.LogSoftmax()的定義也很直觀了:
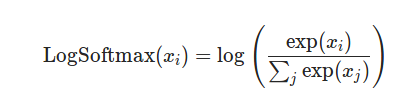
果不其然就是Softmax取了個log���?�?梢詫憘€代碼測試一下:
import torch
import torch.nn as nn
a = torch.Tensor([1,2,3])
#定義Softmax
softmax = nn.Softmax()
sm_a = softmax=nn.Softmax()
print(sm)
#輸出:tensor([0.0900, 0.2447, 0.6652])
#定義LogSoftmax
logsoftmax = nn.LogSoftmax()
lsm_a = logsoftmax(a)
print(lsm_a)
#輸出tensor([-2.4076, -1.4076, -0.4076])�����,其中l(wèi)n(0.0900)=-2.4076
nn.NLLLoss
上面說過nn.CrossEntropy()是nn.LogSoftmax()和nn.NLLLoss的結合��,nn.NLLLoss官網(wǎng)給的定義是這樣的:
The negative log likelihood loss. It is useful to train a classification problem with C classes
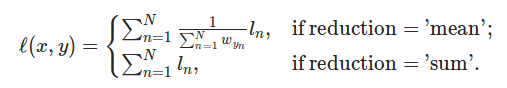
負對數(shù)似然損失 ���,看起來好像有點晦澀難懂,寫個代碼測試一下:
import torch
import torch.nn
a = torch.Tensor([[1,2,3]])
nll = nn.NLLLoss()
target1 = torch.Tensor([0]).long()
target2 = torch.Tensor([1]).long()
target3 = torch.Tensor([2]).long()
#測試
n1 = nll(a,target1)
#輸出:tensor(-1.)
n2 = nll(a,target2)
#輸出:tensor(-2.)
n3 = nll(a,target3)
#輸出:tensor(-3.)
看起來nn.NLLLoss做的事情是取出a中對應target位置的值并取負號�����,比如target1=0���,就取a中index=0位置上的值再取負號為-1��,那這樣做有什么意義呢����,要結合nn.CrossEntropy往下看��。
nn.CrossEntropy
看下官網(wǎng)給的nn.CrossEntropy()的表達式:
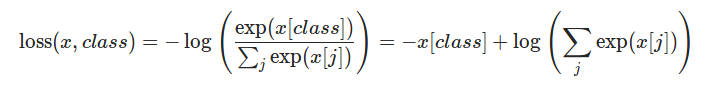
看起來應該是softmax之后取了個對數(shù),寫個簡單代碼測試一下:
import torch
import torch.nn as nn
a = torch.Tensor([[1,2,3]])
target = torch.Tensor([2]).long()
logsoftmax = nn.LogSoftmax()
ce = nn.CrossEntropyLoss()
nll = nn.NLLLoss()
#測試CrossEntropyLoss
cel = ce(a,target)
print(cel)
#輸出:tensor(0.4076)
#測試LogSoftmax+NLLLoss
lsm_a = logsoftmax(a)
nll_lsm_a = nll(lsm_a,target)
#輸出tensor(0.4076)
看來直接用nn.CrossEntropy和nn.LogSoftmax+nn.NLLLoss是一樣的結果�����。為什么這樣呢����,回想下交叉熵的表達式:
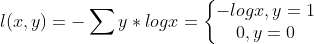
其中y是label,x是prediction的結果���,所以其實交叉熵損失就是負的target對應位置的輸出結果x再取-log�。這個計算過程剛好就是先LogSoftmax()再NLLLoss()���。
所以我認為nn.CrossEntropyLoss其實應該叫做softmaxloss更為合理一些�,這樣就不會誤解了���。
nn.BCELoss
你以為這就完了嗎�,其實并沒有�����。還有一類損失叫做BCELoss�,寫全了的話就是Binary Cross Entropy Loss���,就是交叉熵應用于二分類時候的特殊形式,一般都和sigmoid一起用���,表達式就是二分類交叉熵:

直覺上和多酚類交叉熵的區(qū)別在于����,不僅考慮了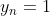 的樣本��,也考慮了
的樣本��,也考慮了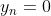 的樣本的損失��。
的樣本的損失��。
總結
nn.LogSoftmax是在softmax的基礎上取自然對數(shù)
nn.NLLLoss是負的似然對數(shù)損失�,但Pytorch的實現(xiàn)就是把對應target上的數(shù)取出來再加個負號���,要在CrossEntropy中結合LogSoftmax來用
BCELoss是二分類的交叉熵損失�,Pytorch實現(xiàn)中和多分類有區(qū)別
Pytorch是個深坑��,讓我們一起扎根使用手冊�,結合實踐踏平這些坑吧暴風哭泣。
以上為個人經(jīng)驗���,希望能給大家一個參考����,也希望大家多多支持腳本之家。
您可能感興趣的文章:- 在Pytorch中使用樣本權重(sample_weight)的正確方法
- pytorch中交叉熵損失(nn.CrossEntropyLoss())的計算過程詳解
- PyTorch的SoftMax交叉熵損失和梯度用法
