本文詳解如何使用pandas查看dataframe的重復數(shù)據(jù)��,判斷是否重復��,以及如何去重
DataFrame.duplicated(subset=None, keep='first')
subset:如果你認為幾個字段重復�,則數(shù)據(jù)重復��,就把那幾個字段以列表形式放到subset后面�。默認是所有字段重復為重復數(shù)據(jù)。
keep:
- 默認為'first' ,也就是如果有重復數(shù)據(jù)�����,則第一條出現(xiàn)的定義為False��,后面的重復數(shù)據(jù)為True����。
- 如果為'last',也就是如果有重復數(shù)據(jù)����,則最后一條出現(xiàn)的定義為False,后面的重復數(shù)據(jù)為True��。
- 如果為False�,則所有重復的為True
下面舉例
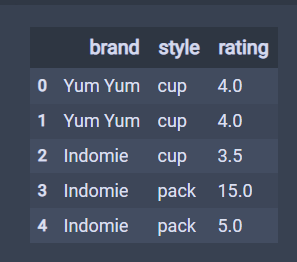
df = pd.DataFrame({
'brand': ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie'],
'style': ['cup', 'cup', 'cup', 'pack', 'pack'],
'rating': [4, 4, 3.5, 15, 5]
})
df
# 默認為keep="first",第一條重復的為False,后面重復的為True
# 一般不會設(shè)置keep,保持keep為默認值���。
df.duplicated()
結(jié)果
0 False
1 True
2 False
3 False
4 False
dtype: bool
# keep="last",,最后一條重復的為False,后面重復的為True
df.duplicated(keep="last")
結(jié)果
0 True
1 False
2 False
3 False
4 False
dtype: bool
# keep=False,,所有重復的為True
df.duplicated(keep=False)
結(jié)果
0 True
1 True
2 False
3 False
4 False
dtype: bool
# sub是子���,subset是子集
# 標記只要brand重復為重復值。
df.duplicated(subset='brand')
結(jié)果
0 False
1 True
2 False
3 True
4 True
dtype: bool
# 只要brand重復brand和style重復的為重復值�。
df.duplicated(subset=['brand','style'])
結(jié)果
0 False
1 True
2 False
3 False
4 True
dtype: bool
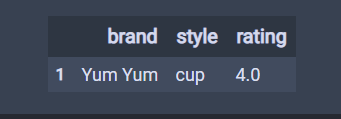
# 顯示重復記錄,通過布爾索引
df[df.duplicated()]
# 查詢重復值的個數(shù)�。
df.duplicated().sum()
結(jié)果
1
到此這篇關(guān)于pandas中DataFrame檢測重復值的實現(xiàn)的文章就介紹到這了,更多相關(guān)pandas DataFrame檢測重復值內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- Pandas實現(xiàn)Dataframe的重排和旋轉(zhuǎn)
- Pandas實現(xiàn)Dataframe的合并
- pandas中DataFrame數(shù)據(jù)合并連接(merge�、join、concat)
- 教你漂亮打印Pandas DataFrames和Series
- 使用pandas忽略行列索引,縱向拼接多個dataframe
- Pandas.DataFrame轉(zhuǎn)置的實現(xiàn)
- Pandas中DataFrame交換列順序的方法實現(xiàn)
- 詳解pandas中利用DataFrame對象的.loc[]��、.iloc[]方法抽取數(shù)據(jù)
- Pandas中兩個dataframe的交集和差集的示例代碼
- Pandas DataFrame求差集的示例代碼
- 淺談pandas dataframe對除數(shù)是零的處理
- Pandas中DataFrame數(shù)據(jù)刪除詳情
