使用pytorch時所遇到的問題總結
1、ubuntu vscode切換虛擬環(huán)境
在ubuntu系統(tǒng)上���,配置工作區(qū)文件夾所使用的虛擬環(huán)境����。之前筆者誤以為只需要在vscode內置的終端上將虛擬環(huán)境切換過來即可���,后來發(fā)現(xiàn)得通過配置vscode的解釋器(interpreter)
具體方法如下:
選中需要配置的文件夾���,然后點擊vscode左下角的寫有“Python ***”的位置(或者使用快捷鍵“ctrl+shift+p”)--》選擇文件夾--》從解釋器列表中選擇要用的解釋器�����。
完成設置后���,會在文件夾下面多出一個名為“.vscode”的文件夾,其中會多出一個名為“settings.json”的文件�����,經過設置后該文件內會多出一個條目來指向虛擬環(huán)境中的python的路徑�,
例如:
python.pythonPath:"/home/lh/anaconda3/envs/pytorch/bin/python"
2、使用DataLoader時報錯:
raise RuntimeError('already started')
出錯位置在使用DataLoader時����,將參數(shù)“num_workers”設置為大于0的值了���,推測原因是沒有打開多線程功能����,解決方法為將num_workers設置為0����。
如果需要要使用多個子線程來加載數(shù)據(jù)����,那么就需要讓主程序在“if __name__ = 'main'"中運行����。
3、pytorch中使用TensorBoard
問題(1):
Import Error:TensorBoard logging requires TensorBoard with Python summary writer installed
這是由于當前的環(huán)境中沒有安裝TensorBoard��。如果電腦上安裝有anaconda�,那么直接使用命令“conda install tensorboard”即可。
問題(2):調出tensorboard界面
當在程序中調用SummaryWriter之后����,在控制臺中會給出如下信息:

其中需要注意的是“--port 41889”。然后我們在控制臺中輸入命令“tensorboard --logdir='log' --port=41889”�,--logdir用來指向之前所指定的日志目錄,--port就是之前控制臺中給出的端口號����。輸入指令后,控制臺中會給出一個網址����,打開該網址就可以在瀏覽器中打開tensorboard界面了���。
4、pytorch使用dataloader時�����,
報出“TypeError:default_collect:batch must contain tensors, numpy arrays, numbers,dicts or lists; found class 'PIL.Image.Image'>”
這是因為在創(chuàng)建torchvision.Dataset對象的時候沒有將數(shù)據(jù)庫內的圖像轉為torch張量�,在創(chuàng)建數(shù)據(jù)庫對象的時候將參數(shù)transform進行如下設置就可以了:transform=transform.ToTensor()。
5����、報錯
RuntimeError:Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same
這是由于傳入模型的數(shù)據(jù)是放在CPU內存中的,而模型本身被放置在GPU內存中了�����。因此只需要將輸入的數(shù)據(jù)放置到GPU內存中就可以解決問該問題了�。
6、pytorch�,同名函數(shù)后面加一個'_'�����,例如:'clamp()'與'clamp_()'
一般來說��,如果函數(shù)后帶了一個下劃線,就意味著在改變當前張量的值的同時返回一個修改后的副本��;如果不帶下劃線���,那么就只返回修改后的副本���,而不改變原來張量的值。
例如:
import torch
a=torch.rand(3)
print('a:{}'.format(a))
print("clamp效果:")
b=a.clamp(0, 0.5)
print('b:{}'.format(b))
print('a:{}'.format(a))
print("clamp_效果:")
b=a.clamp_(0, 0.5)
print('b:{}'.format(b))
print('a:{}'.format(a))
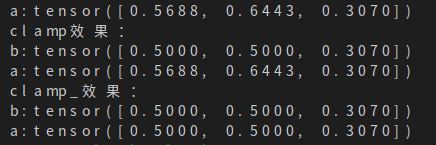
結果為如下圖��,可見張量a在調用clamp_函數(shù)后其本身的值也會發(fā)生改變���,但是調用clamp的時候則只會返回一個修改后的副本����。
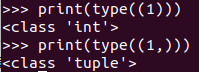
7�����、python中(1)與(1,)的區(qū)別
‘(1)'這種寫法得到的是一個int類型的數(shù)據(jù)���,而‘(1, )'得到的是一個turple類型的數(shù)據(jù)���。驗證如下:
8�����、tqdm進度條
tqdm.update()所傳入的參數(shù)指的是進度條前進的步長���,而不是當前進度。
補充:Pytorch中常見的報錯解決方案
本文用于記錄所在pytorch所遇到過的運行時錯誤�,持續(xù)更新。
1��、變量所在設備(CPU��,GPU)不一致問題
RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.FloatTensor) should be the same
可能原因:現(xiàn)在假設代碼要在GPU上運行��,并且你已經進行my_model.to(device)操作了�����。注意只有my_model中的屬性(也就是self.開頭的變量)才會進行.to(device)��。如果出現(xiàn)這個錯誤�,可能是有的中間變量需要手動再顯式地.to(device)一下~
2、在Conv2d中padding或stride的參數(shù)個數(shù)錯誤的問題
RuntimeError: expected padding to be a single integer value or a list of 1 values to match the convolution dimensions, but got padding=[0, 0]
原因一:
對于一張二維圖片來說��,它的padding也是二維的�����,即橫�、縱方向上都需要設置padding(當然這兩個數(shù)字一般是一樣的)。現(xiàn)在為什么提示我們padding應該是一維的呢���?一定是輸入數(shù)據(jù)維度不對�。

原因二:
上面說的是最可能的情況�,如果你發(fā)現(xiàn)圖片已經是四維的卻還有這個報錯,請檢查你Conv2d()的輸入參數(shù)���。
例如����,如果你把stride設置為一維的[3]而不是二維3(注意3會被自動處理成[3, 3])�����,同時padding為二維的0�。
pytorch發(fā)現(xiàn)stride是一維的,而padding卻是二維的����,就會報錯�����。
3��、inplace operation問題
one of the variables needed for gradient computation has been modified by an inplace operationone of the variables needed for gradient computation has been modified by an inplace operation
inplace操作可能會使得backward無法進行(因為當前Tensor可能會在另一個地方被用到)�,比如forward出現(xiàn)了如下代碼:
你可能需要該成:
以上為個人經驗����,希望能給大家一個參考,也希望大家多多支持腳本之家���。
您可能感興趣的文章:- Pytorch高階OP操作where�����,gather原理
- Pytorch中的gather使用方法
- 淺談Pytorch中的torch.gather函數(shù)的含義
- Pytorch深度學習gather一些使用問題解決方案
