pytorch 權重weight 與 梯度grad 可視化
查看特定layer的權重以及相應的梯度信息
打印模型
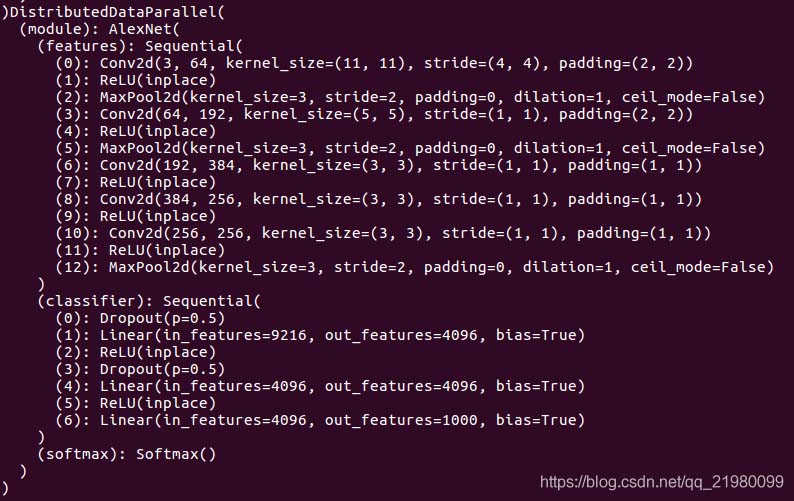
觀察到model下面有module的key�����,module下面有features的key���, features下面有(0)的key�����,這樣就可以直接打印出weight了
在pdb debug界面輸入p model.module.features[0].weight��,就可以看到weight����,輸入 p model.module.features[0].weight.grad 就可以查看梯度信息�。
中間變量的梯度 : .register_hook
pytorch 為了節(jié)省顯存�,在反向傳播的過程中只針對計算圖中的葉子結點(leaf variable)保留了梯度值(gradient)�����。但對于開發(fā)者來說�,有時我們希望探測某些中間變量(intermediate variable) 的梯度來驗證我們的實現是否有誤,這個過程就需要用到 tensor的register_hook接口
grads = {}
def save_grad(name):
def hook(grad):
grads[name] = grad
return hook
x = torch.randn(1, requires_grad=True)
y = 3*x
z = y * y
# 為中間變量注冊梯度保存接口���,存儲梯度時名字為 y���。
y.register_hook(save_grad('y'))
# 反向傳播
z.backward()
# 查看 y 的梯度值
print(grads['y'])
打印網絡回傳梯度
net.named_parameters()
parms.requires_grad 表示該參數是否可學習,是不是frozen的���;
parm.grad 打印該參數的梯度值����。
net = your_network().cuda()
def train():
...
outputs = net(inputs)
loss = criterion(outputs, targets)
loss.backward()
for name, parms in net.named_parameters():
print('-->name:', name, '-->grad_requirs:',parms.requires_grad, \
' -->grad_value:',parms.grad)
查看pytorch產生的梯度
[x.grad for x in self.optimizer.param_groups[0]['params']]
pytorch模型可視化及參數計算
我們在設計完程序以后希望能對我們的模型進行可視化��,pytorch這里似乎沒有提供相應的包直接進行調用��,下面把代碼貼出來:
import torch
from torch.autograd import Variable
import torch.nn as nn
from graphviz import Digraph
def make_dot(var, params=None):
if params is not None:
assert isinstance(params.values()[0], Variable)
param_map = {id(v): k for k, v in params.items()}
node_attr = dict(style='filled',
shape='box',
align='left',
fontsize='12',
ranksep='0.1',
height='0.2')
dot = Digraph(node_attr=node_attr, graph_attr=dict(size="12,12"))
seen = set()
def size_to_str(size):
return '('+(', ').join(['%d' % v for v in size])+')'
def add_nodes(var):
if var not in seen:
if torch.is_tensor(var):
dot.node(str(id(var)), size_to_str(var.size()), fillcolor='orange')
elif hasattr(var, 'variable'):
u = var.variable
name = param_map[id(u)] if params is not None else ''
node_name = '%s\n %s' % (name, size_to_str(u.size()))
dot.node(str(id(var)), node_name, fillcolor='lightblue')
else:
dot.node(str(id(var)), str(type(var).__name__))
seen.add(var)
if hasattr(var, 'next_functions'):
for u in var.next_functions:
if u[0] is not None:
dot.edge(str(id(u[0])), str(id(var)))
add_nodes(u[0])
if hasattr(var, 'saved_tensors'):
for t in var.saved_tensors:
dot.edge(str(id(t)), str(id(var)))
add_nodes(t)
add_nodes(var.grad_fn)
return dot
我們在我們的模型下面直接進行調用就可以了����,例如:
if __name__ == "__main__":
model = DeepLab(backbone='resnet', output_stride=16)
input = torch.rand(1, 3, 53, 53)
output = model(input)
g = make_dot(output)
g.view()
params = list(net.parameters())
k = 0
for i in params:
l = 1
print("該層的結構:" + str(list(i.size())))
for j in i.size():
l *= j
print("該層參數和:" + str(l))
k = k + l
print("總參數數量和:" + str(k))
模型部分可視化結果:
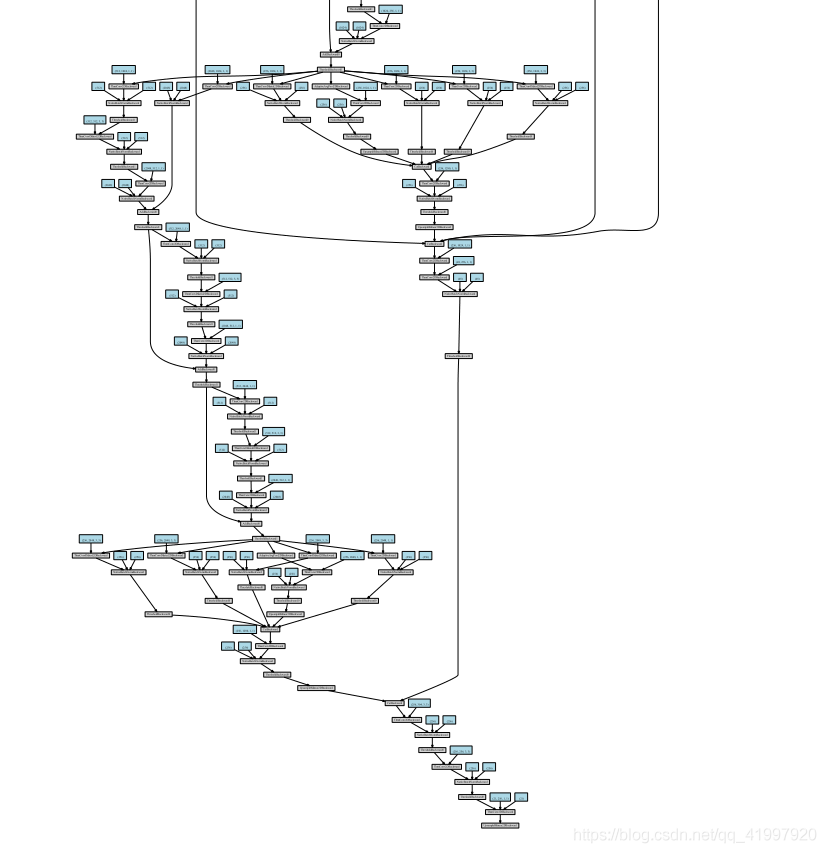
參數計算:

以上為個人經驗,希望能給大家一個參考�,也希望大家多多支持腳本之家。
您可能感興趣的文章:- 可視化pytorch 模型中不同BN層的running mean曲線實例
- pytorch使用tensorboardX進行l(wèi)oss可視化實例
- pytorch對梯度進行可視化進行梯度檢查教程
- pytorch實現mnist數據集的圖像可視化及保存
- 使用pytorch實現可視化中間層的結果
- pytorch 可視化feature map的示例代碼
- pytorch 模型可視化的例子
- Pytorch可視化的幾種實現方法
