一��、所需工具
**Python版本:**3.5.4(64bit)
二�、相關(guān)模塊
- opencv_python模塊
- sklearn模塊
- numpy模塊
- dlib模塊
- 一些Python自帶的模塊�����。
三���、環(huán)境搭建
(1)安裝相應(yīng)版本的Python并添加到環(huán)境變量中;
(2)pip安裝相關(guān)模塊中提到的模塊�。
例如:

若pip安裝報錯,請自行到:
http://www.lfd.uci.edu/~gohlke/pythonlibs/
下載pip安裝報錯模塊的whl文件�,并使用:
pip install whl文件路徑+whl文件名安裝。
例如:
(已在相關(guān)文件中提供了編譯好的用于dlib庫安裝的whl文件——>因為這個庫最不好裝)

參考文獻鏈接
【1】xxxPh.D.的博客
http://www.learnopencv.com/computer-vision-for-predicting-facial-attractiveness/
【2】華南理工大學(xué)某實驗室
http://www.hcii-lab.net/data/SCUT-FBP/EN/introduce.html
四��、主要思路
(1)模型訓(xùn)練
用了PCA算法對特征進行了壓縮降維�;
然后用隨機森林訓(xùn)練模型。
數(shù)據(jù)源于網(wǎng)絡(luò)�,據(jù)說數(shù)據(jù)“發(fā)源地”就是華南理工大學(xué)某實驗室,因此我在參考文獻上才加上了這個實驗室的鏈接�����。
(2)提取人臉關(guān)鍵點
主要使用了dlib庫����。
使用官方提供的模型構(gòu)建特征提取器。
(3)特征生成
完全參考了xxxPh.D.的博客。
(4)顏值預(yù)測
利用之前的數(shù)據(jù)和模型進行顏值預(yù)測�。
使用方式
有特殊疾病者請慎重嘗試預(yù)測自己的顏值,本人不對顏值預(yù)測的結(jié)果和帶來的所有負面影響負責?���。?��!
言歸正傳����。
環(huán)境搭建完成后�����,解壓相關(guān)文件中的Face_Value.rar文件�����,cmd窗口切換到解壓后的*.py文件所在目錄�。
例如:
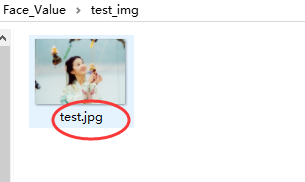
打開test_img文件夾,將需要預(yù)測顏值的照片放入并重命名為test.jpg��。
例如:
若嫌麻煩或者有其他需求�,請自行修改:
getLandmarks.py文件中第13行�。
最后依次運行:
train_model.py(想直接用我模型的請忽略此步)
# 模型訓(xùn)練腳本
import numpy as np
from sklearn import decomposition
from sklearn.ensemble import RandomForestRegressor
from sklearn.externals import joblib
# 特征和對應(yīng)的分數(shù)路徑
features_path = './data/features_ALL.txt'
ratings_path = './data/ratings.txt'
# 載入數(shù)據(jù)
# 共500組數(shù)據(jù)
# 其中前480組數(shù)據(jù)作為訓(xùn)練集�����,后20組數(shù)據(jù)作為測試集
features = np.loadtxt(features_path, delimiter=',')
features_train = features[0: -20]
features_test = features[-20: ]
ratings = np.loadtxt(ratings_path, delimiter=',')
ratings_train = ratings[0: -20]
ratings_test = ratings[-20: ]
# 訓(xùn)練模型
# 這里用PCA算法對特征進行了壓縮和降維�。
# 降維之后特征變成了20維��,也就是說特征一共有500行���,每行是一個人的特征向量���,每個特征向量有20個元素。
# 用隨機森林訓(xùn)練模型
pca = decomposition.PCA(n_components=20)
pca.fit(features_train)
features_train = pca.transform(features_train)
features_test = pca.transform(features_test)
regr = RandomForestRegressor(n_estimators=50, max_depth=None, min_samples_split=10, random_state=0)
regr = regr.fit(features_train, ratings_train)
joblib.dump(regr, './model/face_rating.pkl', compress=1)
# 訓(xùn)練完之后提示訓(xùn)練結(jié)束
print('Generate Model Successfully!')
getLandmarks.py
# 人臉關(guān)鍵點提取腳本
import cv2
import dlib
import numpy
# 模型路徑
PREDICTOR_PATH = './model/shape_predictor_68_face_landmarks.dat'
# 使用dlib自帶的frontal_face_detector作為人臉提取器
detector = dlib.get_frontal_face_detector()
# 使用官方提供的模型構(gòu)建特征提取器
predictor = dlib.shape_predictor(PREDICTOR_PATH)
face_img = cv2.imread("test_img/test.jpg")
# 使用detector進行人臉檢測��,rects為返回的結(jié)果
rects = detector(face_img, 1)
# 如果檢測到人臉
if len(rects) >= 1:
print("{} faces detected".format(len(rects)))
else:
print('No faces detected')
exit()
with open('./results/landmarks.txt', 'w') as f:
f.truncate()
for faces in range(len(rects)):
# 使用predictor進行人臉關(guān)鍵點識別
landmarks = numpy.matrix([[p.x, p.y] for p in predictor(face_img, rects[faces]).parts()])
face_img = face_img.copy()
# 使用enumerate函數(shù)遍歷序列中的元素以及它們的下標
for idx, point in enumerate(landmarks):
pos = (point[0, 0], point[0, 1])
f.write(str(point[0, 0]))
f.write(',')
f.write(str(point[0, 1]))
f.write(',')
f.write('\n')
f.close()
# 成功后提示
print('Get landmarks successfully')
getFeatures.py
# 特征生成腳本
# 具體原理請參見參考論文
import math
import numpy
import itertools
def facialRatio(points):
x1 = points[0]
y1 = points[1]
x2 = points[2]
y2 = points[3]
x3 = points[4]
y3 = points[5]
x4 = points[6]
y4 = points[7]
dist1 = math.sqrt((x1-x2)**2 + (y1-y2)**2)
dist2 = math.sqrt((x3-x4)**2 + (y3-y4)**2)
ratio = dist1/dist2
return ratio
def generateFeatures(pointIndices1, pointIndices2, pointIndices3, pointIndices4, allLandmarkCoordinates):
size = allLandmarkCoordinates.shape
if len(size) > 1:
allFeatures = numpy.zeros((size[0], len(pointIndices1)))
for x in range(0, size[0]):
landmarkCoordinates = allLandmarkCoordinates[x, :]
ratios = []
for i in range(0, len(pointIndices1)):
x1 = landmarkCoordinates[2*(pointIndices1[i]-1)]
y1 = landmarkCoordinates[2*pointIndices1[i] - 1]
x2 = landmarkCoordinates[2*(pointIndices2[i]-1)]
y2 = landmarkCoordinates[2*pointIndices2[i] - 1]
x3 = landmarkCoordinates[2*(pointIndices3[i]-1)]
y3 = landmarkCoordinates[2*pointIndices3[i] - 1]
x4 = landmarkCoordinates[2*(pointIndices4[i]-1)]
y4 = landmarkCoordinates[2*pointIndices4[i] - 1]
points = [x1, y1, x2, y2, x3, y3, x4, y4]
ratios.append(facialRatio(points))
allFeatures[x, :] = numpy.asarray(ratios)
else:
allFeatures = numpy.zeros((1, len(pointIndices1)))
landmarkCoordinates = allLandmarkCoordinates
ratios = []
for i in range(0, len(pointIndices1)):
x1 = landmarkCoordinates[2*(pointIndices1[i]-1)]
y1 = landmarkCoordinates[2*pointIndices1[i] - 1]
x2 = landmarkCoordinates[2*(pointIndices2[i]-1)]
y2 = landmarkCoordinates[2*pointIndices2[i] - 1]
x3 = landmarkCoordinates[2*(pointIndices3[i]-1)]
y3 = landmarkCoordinates[2*pointIndices3[i] - 1]
x4 = landmarkCoordinates[2*(pointIndices4[i]-1)]
y4 = landmarkCoordinates[2*pointIndices4[i] - 1]
points = [x1, y1, x2, y2, x3, y3, x4, y4]
ratios.append(facialRatio(points))
allFeatures[0, :] = numpy.asarray(ratios)
return allFeatures
def generateAllFeatures(allLandmarkCoordinates):
a = [18, 22, 23, 27, 37, 40, 43, 46, 28, 32, 34, 36, 5, 9, 13, 49, 55, 52, 58]
combinations = itertools.combinations(a, 4)
i = 0
pointIndices1 = []
pointIndices2 = []
pointIndices3 = []
pointIndices4 = []
for combination in combinations:
pointIndices1.append(combination[0])
pointIndices2.append(combination[1])
pointIndices3.append(combination[2])
pointIndices4.append(combination[3])
i = i+1
pointIndices1.append(combination[0])
pointIndices2.append(combination[2])
pointIndices3.append(combination[1])
pointIndices4.append(combination[3])
i = i+1
pointIndices1.append(combination[0])
pointIndices2.append(combination[3])
pointIndices3.append(combination[1])
pointIndices4.append(combination[2])
i = i+1
return generateFeatures(pointIndices1, pointIndices2, pointIndices3, pointIndices4, allLandmarkCoordinates)
landmarks = numpy.loadtxt("./results/landmarks.txt", delimiter=',', usecols=range(136))
featuresALL = generateAllFeatures(landmarks)
numpy.savetxt("./results/my_features.txt", featuresALL, delimiter=',', fmt = '%.04f')
print("Generate Feature Successfully!")
Predict.py
# 顏值預(yù)測腳本
from sklearn.externals import joblib
import numpy as np
from sklearn import decomposition
pre_model = joblib.load('./model/face_rating.pkl')
features = np.loadtxt('./data/features_ALL.txt', delimiter=',')
my_features = np.loadtxt('./results/my_features.txt', delimiter=',')
pca = decomposition.PCA(n_components=20)
pca.fit(features)
predictions = []
if len(my_features.shape) > 1:
for i in range(len(my_features)):
feature = my_features[i, :]
feature_transfer = pca.transform(feature.reshape(1, -1))
predictions.append(pre_model.predict(feature_transfer))
print('照片中的人顏值得分依次為(滿分為5分):')
k = 1
for pre in predictions:
print('第%d個人:' % k, end='')
print(str(pre)+'分')
k += 1
else:
feature = my_features
feature_transfer = pca.transform(feature.reshape(1, -1))
predictions.append(pre_model.predict(feature_transfer))
print('照片中的人顏值得分為(滿分為5分):')
k = 1
for pre in predictions:
print(str(pre)+'分')
k += 1
到此這篇關(guān)于Python實現(xiàn)對照片中的人臉進行顏值預(yù)測的文章就介紹到這了,更多相關(guān)Python對人臉進行顏值預(yù)測內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家�!
您可能感興趣的文章:- OpenCV圖像修復(fù)cv2.inpaint()的使用
- python 用opencv實現(xiàn)圖像修復(fù)和圖像金字塔
- OpenCV中圖像通道操作的深入講解
- Python深度學(xué)習(xí)pytorch實現(xiàn)圖像分類數(shù)據(jù)集
- Python實現(xiàn)老照片修復(fù)之上色小技巧
